前言
在进行 IO 操作的过程中, CPU 和内存都是高速的存储设备, 因此磁盘的读写会成为整个 IO 的瓶颈所在, 因此处理好磁盘的读写, 能够提升应用整体的流畅度
了解了 IO 优化的相关思路, 这里了解一下 Android 端 IO 的监控和优化技术
一. IO 监控
IO 监控的意义如下
- 在开发过程中, 记录 IO 耗时较长的场景, 有利于代码优化
- 在线上, 可以监控不同机型的 IO 情况, 便于根据设备机型去做针对性的优化
关于 IO 的监控, 主要的思路有 Java Hook 和 Native Hook
一) Java Hook
Java Hook 主要有插桩和动态代理两种方式
- 插桩: 无法覆盖所有的 IO 操作, 大量系统代码也存在 IO 操作
- 动态代理:
- 不同的 Android 版本, Java 层的实现变更比较大, 有大量的版本适配性工作
- 但很多系统级的 IO 操作, 是直接调用 native 层的函数, 因此只做 java 层的 hook, 无法覆盖所有场景
因此想要实现 IO 监控, 最好的方式是使用 Native 层的 hook
二) Native Hook
Java 层的 IO 操作, 最终都会对应到 Linux 的 open/read/write/close 操作, 因此只需要 hook 这些函数就能够达到目的
int open(const char *pathname, int flags, mode_t mode);
ssize_t read(int fd, void *buf, size_t size);
ssize_t write(int fd, const void *buf, size_t size); write_cuk
int close(int fd);
这些函数的实现, 定义在 libopenjdkjvm.so, libjavacore.so 和 libopenjdk.so 中, 可以覆盖到所有的 java 层 IO 调用
这里以 Tencent 开源库 Matrix-io-canary 中 IO 操作为例, 看看它是如何实现的
Matrix IO 监控
// io_canary_jin.cc
namespace iocanary {
......
const static char* TARGET_MODULES[] = {
"libopenjdkjvm.so",
"libjavacore.so",
"libopenjdk.so"
};
extern "C" {
JNIEXPORT jboolean JNICALL
Java_com_tencent_matrix_iocanary_core_IOCanaryJniBridge_doHook(JNIEnv *env, jclass type) {
// for 循环要 hook 的动态库
for (int i = 0; i < TARGET_MODULE_COUNT; ++i) {
const char* so_name = TARGET_MODULES[i];
// 1. 通过 elfhook_open 找到 so 库的信息, 并且使用 loaded_soinfo 描述
loaded_soinfo* soinfo = elfhook_open(so_name);
......
// elfhook_replace 有两个作用, 一是将库中 open 函数替换成 ProxyOpen 的函数
// 二是将原来的函数实现保存在传出参数 original_open 中
// 2. hook open 函数
elfhook_replace(soinfo, "open", (void*)ProxyOpen, (void**)&original_open);
......
if (is_libjavacore) {
// 3. hook read 函数
if (!elfhook_replace(soinfo, "read", (void*)ProxyRead, (void**)&original_read)) {
......
}
// 4. hook write 函数
if (!elfhook_replace(soinfo, "write", (void*)ProxyWrite, (void**)&original_write)) {
.......
}
}
// 5. hook close 函数
elfhook_replace(soinfo, "close", (void*)ProxyClose, (void**)&original_close);
......
}
return true;
}
......
}
......
}
好的, 可以看到 Matrix 的 hook 操作有两步
- 找到对应的 so 库的内存地址信息
- 替换 so 库中的函数实现
其 elfhook_xx 函数定义在 matrix-android-commons/src/main/cpp/elf_hook 中, 感兴趣的可以点击查看
这里以 read 的 hook 函数实现为例
// io_canary_jin.cc
namespace iocanary {
......
extern "C" {
......
/**
* Proxy for read: callback to the java layer
*/
ssize_t ProxyRead(int fd, void *buf, size_t size) {
// 如果不是主线程, 则直接调用原始方法
if(!IsMainThread()) {
return original_read(fd, buf, size);
}
// 1. 记录开始时间
int64_t start = GetTickCountMicros();
// 2. 调用系统实现
size_t ret = original_read(fd, buf, size);
// 3. 记录结束时间
long read_cost_μs = GetTickCountMicros() - start;
// 4, 回调到 java 层
iocanary::IOCanary::Get().OnRead(fd, buf, size, ret, read_cost_μs);
return ret;
}
......
}
}
好的, 可以看到其对于 read 函数的 Hook 也非常的清晰, 整体流程如下图所示
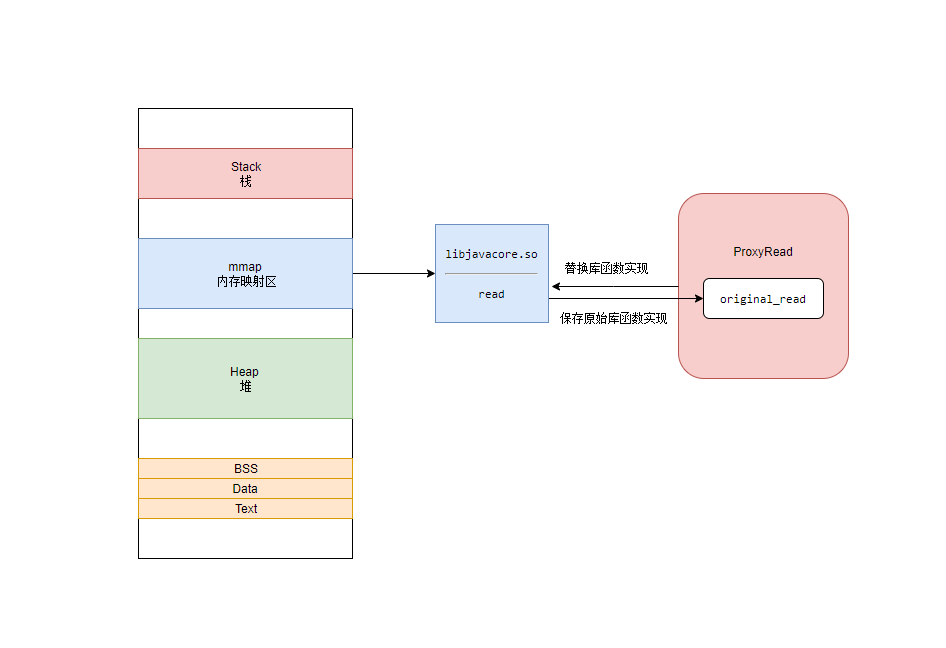
可能是考虑到多线程同步的问题 这里只对主线程做了 hook 操作, 说明还是有优化空间的, 其 Github issue 如下 https://github.com/Tencent/matrix/issues/146
三) 回顾
IO 监控技术主要有 Java Hook 和 Native Hook 两种实现方式, Native Hook 具有如下优势
- Native 层的 API 变更比较小, 版本控制方便
- 能够获得比 Java 代码更高的性能
当然 Native Hook 的实现难度比起 Java Hook 还是要高许多的, 关于 IO 监控的开源库还有 Facebook 的 Atrace, 感兴趣可以点击查看
二. IO 优化
IO 优化及对磁盘 IO 的优化, 有以下几个角度
- 从手机厂商的角度
- 使用更大的内存
- 当内存不足时, Linux 会回收 PageCache 页缓存, 这就导致文件读写操作直接落盘, 直接 IO 带来底下的性能
- 使用更好的闪存
- 闪存重复写入, 需要先进行擦除操作, 低端机磁盘碎片多, 剩余空间少, 一个内存页的写入会引起整个磁盘块的迁移, 造成耗时操作
- 优化磁盘的文件系统
- Linux 目前主流的是 ext4 文夹系统, 华为在 EMUI5.0 之后使用了 F2FS 取代了 ext4, 在系统小文件的随机读写方面比 ext4 更快
- 使用更大的内存
- 从开发者角度
- 选择合适的文件读写操作
- read/write
- mmap
- IO 方式的选择
- 多线程阻塞 IO
- 异步IO (IO)
- 选择合适的文件读写操作
这里我们分析一下, 从开发者的角度我们可以坐的工作有哪些
一) 选择合适的文件读写操作
1. 缓存 IO
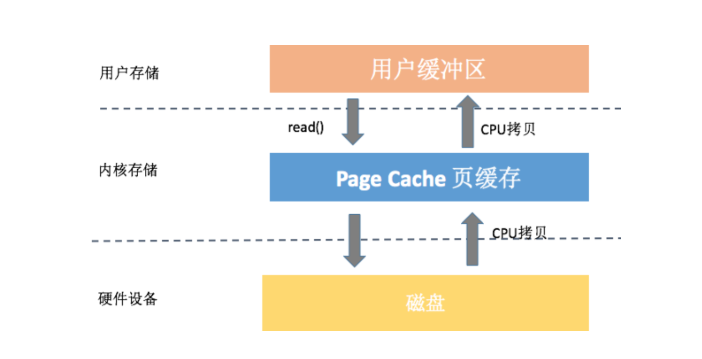
对于读操作
- 内核首先尝试从页缓存中获取数据, 命中后直接拷贝到用户空间
- 未命中则从磁盘拷贝到页缓存, 再从页缓存拷贝到用户空间
对于写操作
- 内核从用户缓存区拷贝到页缓存
- 交由页缓存控制什么时候将数据 flush 到磁盘
// flush 每隔 5 秒执行一次
vm.dirty_writeback_centisecs = 500
// 内存中驻留 30 秒以上的脏数据将由 flush 在下一次执行时写入磁盘
vm.dirty_expire_centisecs = 3000
// 指示若脏页占总物理内存 10%以上,则触发 flush 把脏数据写回磁盘
vm.dirty_background_ratio = 10
// 系统所能拥有的最大脏页缓存的总大小
vm.dirty_ratio = 20
设计目的
PageCache 页缓存, 可以避免每次都直接落盘带来的性能损耗
- 即使在内存上拷贝 100 次, 也比真正读一次磁盘速度要快
适用场景
- 允许极低概率数据丢失的可能
- 突然断电会导致数据丢失
- 对读写速度有较高的要求
2. 直接 IO
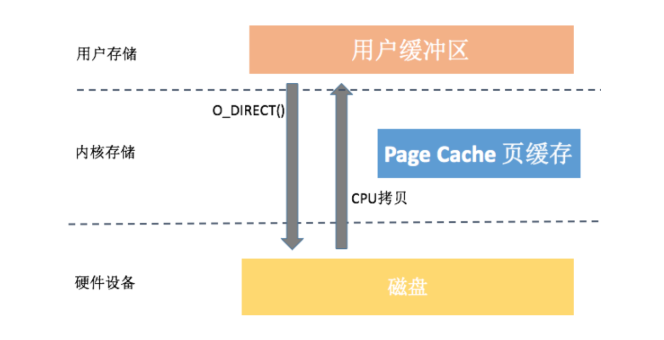
读操作
- 内核直接从磁盘拷贝到用户的缓冲区
写操作
- 内核从用户空间内存直接拷贝到磁盘
每次 IO 操作都直接落盘, 减少了一次数据拷贝
目的
通过这种方式能够简单粗暴的保证数据能够及时落盘
适用场景
- 对文件读写的速度要求不高
- 严格的保证数据不会丢失
3. mmap
mmap 系统调用是 Linux 提供的内存映射, 它有两种映射方式分别是匿名映射和文件映射
void* mmap(void* start,size_t length,int prot,int flags,int fd,off_t offset);
对于匿名映射
- 根据 length 找寻一块空间的虚拟内存, 这块虚拟内存, 用户空间和内核空间都可以操作, 无需在两者之间进行数据拷贝
对于文件映射
- 除了找寻虚拟内存之外, 还会让这块 vm_area 的结构体关联上文件系统的 ops, 即操作这块内存就等同于直接操作文件了
优势
- 省去了在用户空间与内核空间之间拷贝的耗时操作
- 拥有 缓存 IO 的所有特性
适用场景
- 适合于对同一块区域频繁读写的情况
- 跨进程通信
- Binder 驱动
二) IO 方式的选取
IO 的选取主要有两种, 分别为 多线程阻塞I/O 和异步 I/O
1. 多线程阻塞 I/O
多线程阻塞 IO 为我们最常用的 IO 方式, 即将 IO 操作放在子线程中执行, 当进行 IO 时, 可能会阻塞子线程等待
Nexus 6P 读取 30 个大小为 40MB 的文件, 线程配置多少比较合理呢?
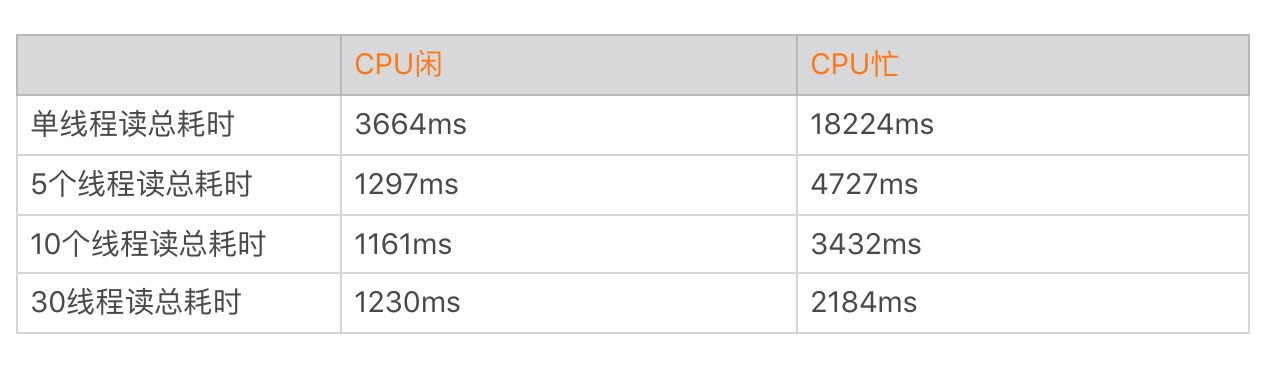
可以看到, 30 个线程带来的收益并不会比 10 个线程来的好, 文件读写受到 I/O 性能瓶颈的影响, 在达到一定速度后, 整体性能就会受到明显影响, 过多的线程反而会增大上下文的开销
2. 异步 I/O
异步 I/O 即将 I/O 以事件的方式通知, 来减少线程切换带来的开销, 不过它使程序变的更加复杂, 其最大的作用不是减少读取文件的耗时, 而是提升 CPU 整体的利用率
Okio 支持同步和异步的 I/O, 做了很多的优化
总结
- IO 的监控: 主要有 Native Hook 和 Java Hook
- Native 层的 API 变更比较小, 版本控制方便
- 能够获得比 Java 代码更高的性能
- IO 的优化
- 选用合适的 IO 方式
- 对于读写速度要求高, 使用缓存 IO
- 对于落盘准确性要求高, 使用直接 IO
- 对于频繁读写的大文件, 使用 mmap
- 编程技巧
- Okio 中 ByteString 和 Buffer 通过重用等技巧, 很大程度上减少 CPU 和内存的消耗
- Buffer 缓冲区的获取与磁盘块大小一致比较合适, 4kb 能够获得最佳性能
- 优化数据结构与算法优化, 降低 IO 操作的频率
- 选用合适的 IO 方式