前言
ServiceManager 的启动, 关于它的启动流程可以点击查看这篇文章
它是 Binder 驱动上下文的管理者, 这里便通过一次完成的 Binder 通信来对学习的知识进行一次汇总, 通过 SystemService 与 ServiceManager 进程的交互, 学习一下整个 Binder 通信的流程
一. Client 发送到 Server 端
在非 ServiceManager 进程中获取 ServiceManager 代理对象的方式为 defaultServiceManager(), 这个方法返回的是 ServiceManager 的代理对象 BpServiceManager
defaultServiceManager()->addService(String16("SampleService"), new SampleService);
接下来看看 addService 这个方法在 BpServiceManager 代理类中的实现
// frameworks/base/libs/binder/IServiceManager.cpp
virtual status_t addService(const String16& name, const sp<IBinder>& service,
bool allowIsolated)
{
Parcel data, reply;
// 1. 将通信参数封装到 data 中
data.writeInterfaceToken(IServiceManager::getInterfaceDescriptor());
data.writeString16(name);
// 将 Binder 本地对象写入 Parcel
data.writeStrongBinder(service);
data.writeInt32(allowIsolated ? 1 : 0);
// 2. 调用 BpBinder 的 transact
status_t err = remote()->transact(ADD_SERVICE_TRANSACTION, data, &reply);
// 3. 读取请求结束后 Server 通过 Binder 驱动返回回来的数据
return err == NO_ERROR ? reply.readExceptionCode() : err;
}
代理实现方法主要做了以下几步操作
- 将通信参数封装到 Parcel data 中
- 写入接口对应的描述
- 写入传入的形参
- 通过 BpBinder 的 transact 向 Binder 驱动发起跨进程调用请求
- 这个操作会阻塞当前线程
- 读取请求结束后 Server 通过 Binder 驱动返回回来的数据
下面我们看看 Binder 代理对象的 transact 函数
// frameworks/native/libs/binder/BpBinder.cpp
status_t BpBinder::transact(
uint32_t code, const Parcel& data, Parcel* reply, uint32_t flags)
{
// mAlive 用于判断 Binder 代理对象所引用的 Binder 本地对象是否存活
if (mAlive) {
// 调用了 IPCThreadState 的 transact 方法
// mHandle 为这个代理对象的句柄值
status_t status = IPCThreadState::self()->transact(
mHandle, code, data, reply, flags);
if (status == DEAD_OBJECT) mAlive = 0;
return status;
}
return DEAD_OBJECT;
}
// frameworks/native/libs/binder/IPCThreadState.cpp
status_t IPCThreadState::transact(int32_t handle,
uint32_t code, const Parcel& data,
Parcel* reply, uint32_t flags)
{
// 进行错误检查
status_t err = data.errorCheck();
if (err == NO_ERROR) {
// 1. 封装请求数据到
err = writeTransactionData(BC_TRANSACTION, flags, handle, code, data, NULL);
}
// TF_ONE_WAY 若为 0 则说明是同步的进程间请求
if ((flags & TF_ONE_WAY) == 0) {
if (reply) {
// 2. 通过 waitForResponse 向 Binder 驱动发送上面封装的 binder_transaction_data 结构体对象
// 操作码为 BC_TRANSACTION
err = waitForResponse(reply);
} else {
......
}
} else {
......
}
return err;
}
BpBinder 的 transact 函数会转发到 IPCThreadState::transact 函数实现, 它的操作如下
- 调用 writeTransactionData 封装请求数据, 指令码为 BC_TRANSACTION
- 通过 waitForResponse 函数, 向 Binder 驱动发起请求获取通信结果
接下来我们一一查看
一) 封装请求数据
// frameworks/native/libs/binder/IPCThreadState.cpp
status_t IPCThreadState::writeTransactionData(int32_t cmd, uint32_t binderFlags,
int32_t handle, uint32_t code, const Parcel& data, status_t* statusBuffer)
{
// 1. 构建 binder_transaction_data 对象
binder_transaction_data tr;
// 赋初始值
tr.target.ptr = 0;
tr.target.handle = handle;
tr.code = code;
tr.flags = binderFlags;
tr.cookie = 0;
tr.sender_pid = 0;
tr.sender_euid = 0;
// 错误检查
const status_t err = data.errorCheck();
if (err == NO_ERROR) {
// 将 Parcel 中的数据保存到 binder_transaction_data 中
tr.data_size = data.ipcDataSize();
tr.data.ptr.buffer = data.ipcData();
tr.offsets_size = data.ipcObjectsCount()*sizeof(binder_size_t);
tr.data.ptr.offsets = data.ipcObjects();
} else if (statusBuffer) {
......
} else {
......
}
// 2. 将 指令码 和 binder_transaction_data 写入到内核缓冲区
// 将 BC_TRANSACTION 这个命令写入 mOut 缓冲区
mOut.writeInt32(cmd);
// 将 tr 这个结构体写入 mOut 缓冲区, 用于后续与 Binder 驱动交互
mOut.write(&tr, sizeof(tr));
return NO_ERROR;
}
writeTransactionData 主要操作如下
- 构建 binder_transaction_data 结构体, 并将 data 写入
- 将 binder_transaction_data 和 指令码 BC_TRANSACTION 写入到 mOut 中
这个 mOut 是通过 mmap 映射的一块 Binder 驱动内核缓冲区, 我们在 ServiceManager 启动时已经分析过了, 这里就不再赘述了, 其写入的数据结构如下

接下来看看 waitForResponse 与 Binder 驱动程序进行交互
二) 将数据发送给 Binder 驱动
status_t IPCThreadState::waitForResponse(Parcel *reply, status_t *acquireResult)
{
uint32_t cmd;
int32_t err;
while (1) {
// 1. 调用了 talkWithDriver() 与 Binder 驱动交互
if ((err=talkWithDriver()) < NO_ERROR) break;
if (err < NO_ERROR) break;
// 2. 处理 Binder 驱动返回的指令
if (mIn.dataAvail() == 0) continue;
cmd = (uint32_t)mIn.readInt32();
switch (cmd) {
......// 处理 Binder 驱动的回复码
}
}
finish:
......
return err;
}
}
可以看到 waitForResponse 中主要操作如下
- 调用 talkWithDriver 通知 Binder 驱动, 处理这次客户端的请求
- 从内核缓冲区 mIn 中读取 Binder 驱动返回的指令码并处理
- 使用 Binder 驱动进行一次跨进程通信的过程中, 会存在多个指令码, 因此对于指令码的处理, 我们遇到时单独分析
下面我们重点看看 talkWithDriver 是如何与 Binder 驱动交互的
talkWithDriver
status_t IPCThreadState::talkWithDriver(bool doReceive)
{
......
// 1. 定义 binder_write_read 结构体, 指定输入缓冲区和输出缓冲区
binder_write_read bwr;
......
// 2. 记录 写到 Binder 驱动的数据信息
const size_t outAvail = (!doReceive || needRead) ? mOut.dataSize() : 0;
// 2.1 记录 写入数据大小
bwr.write_size = outAvail;
// 2.2 记录 数据首地址
bwr.write_buffer = (uintptr_t)mOut.data();
// 3. 记录 Binder 驱动返回的数据信息
if (doReceive && needRead) {
// 3.1 记录 返回数据大小
bwr.read_size = mIn.dataCapacity();
// 3.2 记录 返回数据的首地址
bwr.read_buffer = (uintptr_t)mIn.data();
} else {
bwr.read_size = 0;
bwr.read_buffer = 0;
}
......
bwr.write_consumed = 0;
bwr.read_consumed = 0;
status_t err;
do {
......
// 4. 通过 ioctl 系统调用, 让 Binder 处理这次通信请求
if (ioctl(mProcess->mDriverFD, BINDER_WRITE_READ, &bwr) >= 0)
err = NO_ERROR;
else
err = -errno;
......
} while (err == -EINTR);
// 5. 处理 Binder 驱动的返回值
if (err >= NO_ERROR) {
// 5.1 将 Binder 驱动已处理的命令协议从 mOut 中移除
if (bwr.write_consumed > 0) {
if (bwr.write_consumed < mOut.dataSize())
mOut.remove(0, bwr.write_consumed);
else
mOut.setDataSize(0);
}
// 5.2 将 Binder 驱动返回的命令协议保存到 mIn 中
if (bwr.read_consumed > 0) {
mIn.setDataSize(bwr.read_consumed);
mIn.setDataPosition(0);
}
return NO_ERROR;
}
return err;
}
talkWithDriver 这个函数非常重要, 它是 Binder 停留在应用程序框架层的最后一个函数, 主要做了如下操作
- 创建 binder_write_read 结构体, 这是 ioctl 作为系统调用的参数发送给 Linux 内核层
- binder_write_read 记录请求数据的大小和缓冲区首地址
- binder_write_read 记录返回值数据的大小和缓冲区首地址
- 通过 ioctl 系统调用, 将 binder_write_read 发送给 Binder 驱动通信, 指令码为 BINDER_WRITE_READ
- 与 Binder 的通信完成
好的, 到这里数据就进入到 Linux 内核了, 下面我们看看 Binder 驱动的文件操作 ioctl 函数是如何处理 BINDER_WRITE_READ 指令的
三) 驱动处理 BINDER_WRITE_READ 指令
// // kernel/goldfish/drivers/staging/android/binder.c
static long binder_ioctl(struct file *filp, unsigned int cmd, unsigned long arg)
{
......
switch (cmd) {
case BINDER_WRITE_READ:
ret = binder_ioctl_write_read(filp, cmd, arg, thread);
if (ret)
goto err;
break;
......
}
static int binder_ioctl_write_read(struct file *filp,
unsigned int cmd, unsigned long arg,
struct binder_thread *thread)
{
int ret = 0;
// 获取当前使用 Binder 驱动进程的描述
struct binder_proc *proc = filp->private_data;
unsigned int size = _IOC_SIZE(cmd);
// 1. 通过 copy_from_user, 拷贝用户空间传递过来的 binder_write_read 结构体
void __user *ubuf = (void __user *)arg;
struct binder_write_read bwr;
......
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
// 2. 处理写操作
if (bwr.write_size > 0) {
ret = binder_thread_write(proc, thread,
bwr.write_buffer,
bwr.write_size,
&bwr.write_consumed);
......
}
// 3. 处理读操作
if (bwr.read_size > 0) {
ret = binder_thread_read(proc, thread, bwr.read_buffer,
bwr.read_size,
&bwr.read_consumed,
filp->f_flags & O_NONBLOCK);
......
}
......
// 4. 通过 copy_to_user, 将内核处理好的 binder_write_read 拷贝到用户空间
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
out:
return ret;
}
关于 binder_ioctl_write_read 函数我们在 ServiceManager 进程启动篇中已经分析过了, 当时我们通过 binder_thread_read 了解了当没有通讯请求时 ServiceManager 是阻塞在这个函数中的
这里我们就详细看看数据是怎么通过 binder_thread_write 发送到 ServiceManager 进程, 如何唤醒 ServiceManager 阻塞的线程的处理通讯请求的
从上面的分析可知, 我们在用户空间时, 是往内核缓冲区中写入了 BC_TRANSACTION 指令和 binder_transaction_data 的结构体数据
因此我们先看看 binder_thread_write 是如何将数据写入到目标进程的
四) 驱动处理 BC_TRANSACTION 指令
// kernel/goldfish/drivers/staging/android/binder.c
static int binder_thread_write(struct binder_proc *proc,
struct binder_thread *thread,binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed)
{
uint32_t cmd;
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
while (ptr < end && thread->return_error == BR_OK) {
// 获取用户空间写到缓冲区的指令码, 复制在 cmd 中
// 由上面可知, cmd 为 BC_TRANSACTION
if (get_user_preempt_disabled(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
......
switch(cmd) {
......
// 处理 BC_TRANSACTION/BC_REPLY
case BC_TRANSACTION:
case BC_REPLY: {
// 1. 获取用户空间写到缓冲区的数据, 使用 transaction_data 结构体来描述
struct binder_transaction_data tr;
if (copy_from_user_preempt_disabled(&tr, ptr, sizeof(tr)))
return -EFAULT;
ptr += sizeof(tr);
// 2. 进行指令码的处理操作
binder_transaction(proc, thread, &tr,
cmd == BC_REPLY, 0);
break;
}
......
}
......
}
}
好的 binder_thread_write 函数中关于 BC_TRANSACTION 指令码的处理如下
- 通过 copy_from_user_preempt_disabled 获取用户空间写入到缓冲区的值, 使用 transaction_data 描述
- 调用 binder_transaction 处理后续操作
从上面的代码中可知, BC_TRANSACTION/BC_REPLY 都是由 binder_transaction 函数处理, binder_transaction 函数是跨进程数据传输的重中之重, 下面我们着重分析它对 BC_TRANSACTION 的处理
binder_transaction 处理 BC_TRANSACTION
// kernel/goldfish/drivers/staging/android/binder.c
static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply,
binder_size_t extra_buffers_size)
{
struct binder_transaction *t;
struct binder_work *tcomplete;
binder_size_t *offp, *off_end;
binder_size_t off_min;
struct binder_proc *target_proc;
struct binder_thread *target_thread = NULL;
struct binder_node *target_node = NULL;
struct list_head *target_list;
wait_queue_head_t *target_wait;
struct binder_transaction *in_reply_to = NULL;
struct binder_transaction_log_entry *e;
uint32_t return_error;
if (reply) {
// 处理 BC_REPLY 指令, 到后面分析
....
} else {
// 处理 BC_TRANSACTION 指令
if (tr->target.handle) {
// 1. 获取 Client 调用的 binder 引用对象
struct binder_ref *ref;
ref = binder_get_ref(proc, tr->target.handle, true);
// 2. 通过引用对象找到其对应的实体对象
target_node = ref->node;
} else {
// 若 handle 为 0, 则表明为 Binder 驱动的上下文管理者 ServiceManager 的 Binder
target_node = context->binder_context_mgr_node;
}
......
// 3. 通过 binder 实体对象, 找对对应的 Server 进程
target_proc = target_node->proc;
......
// 4. 尝试在 Server 进程找到最合适的空闲线程去处理这次 Client 端的请求
if (!(tr->flags & TF_ONE_WAY) && thread->transaction_stack) {
struct binder_transaction *tmp;
tmp = thread->transaction_stack;
......
while (tmp) {
if (tmp->from && tmp->from->proc == target_proc)
target_thread = tmp->from;
tmp = tmp->from_parent;
}
}
}
// 4.1 将目标线程的 todo 队列和 wait 队列保存到成员变量中
if (target_thread) {
// 更新成员变量指向目标线程中的相关属性
target_list = &target_thread->todo;
target_wait = &target_thread->wait;
} else {
// 更新成员变量指向目标进程中的相关属性
target_list = &target_proc->todo;
target_wait = &target_proc->wait;
};
// 5. 创建跨进程通信事务
// 5.1 创建服务端 Binder 通信事务 binder_transaction t
t = kzalloc_preempt_disabled(sizeof(*t));
// 5.2 创建客户端 Binder 通信事务 binder_transaction tcomplete
tcomplete = kzalloc_preempt_disabled(sizeof(*tcomplete));
// 6. 将 Client 端数据拷贝到 Server 端的内核缓冲区
// 6.1 在找寻服务端的一块缓冲区
t->buffer = binder_alloc_buf(target_proc, tr->data_size, tr->offsets_size, extra_buffers_size, !reply && (t->flags & TF_ONE_WAY));
......
// 服务端内核缓冲区偏移位置
offp = (binder_size_t *)(t->buffer->data +
ALIGN(tr->data_size, sizeof(void *)));
// 6.2 拷贝客户端数据到服务端的内核缓冲区
if (copy_from_user(t->buffer->data, (const void __user *)(uintptr_t)
tr->data.ptr.buffer, tr->data_size)) {
binder_user_error("%d:%d got transaction with invalid data ptr\n",
proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
goto err_copy_data_failed;
}
// 7. 处理缓冲区数据中存在 Binder 本地对象的情况
for (; offp < off_end; offp++) {
struct flat_binder_object *fp;
fp = (struct flat_binder_object *) (t->buffer->data + *offp)
switch (fp->type) {
// 我们开始的时候调用的是 put 方法
case BINDER_TYPE_BINDER:
case BINDER_TYPE_WEAK_BINDER: {
struct binder_ref *ref;
struct binder_node* node = binder_get_node(proc, fp->binder);
// 7.1 若 Client 进程在内核中不存在该 Binder 本地对象对应的 binder_node 则调用 binder_new_node 创建一个
if (node == NULL) {
node = binder_new_node(proc, fp->binder, fp->cookie);
}
// 7.2 获取需要 Server 端对应的 binder_ref, 没有则创建一个
ref = binder_get_ref_for_node(target_proc, node);
} break;
}
......
// 8. 将 t 的工作项设置为 BINDER_WORK_TRANSACTION
t->work.type = BINDER_WORK_TRANSACTION;
// 添加到 Server 的工作队列的尾部
list_add_tail(&t->work.entry, target_list);
// 9. 将 tcomplete 的工作项设置为 BINDER_WORK_TRANSACTION_COMPLETE
tcomplete->type = BINDER_WORK_TRANSACTION_COMPLETE;
// 添加到 Client 的工作队列中
list_add_tail(&tcomplete->entry, &thread->todo);
// 10. 唤醒 Server 端目标线线程去执行 BINDER_WORK_TRANSACTION 任务
if (target_wait) {
wake_up_interruptible(target_wait);
}
return;
}
可以看到 binder 驱动的跨进程通信的主要操作都在 binder_transaction 中了, 关于 BC_TRANSACTION 指令它处理的事务如下
- 获取 Client 调用的 Binder 引用对象 binder_ref
- 通过 Binder 引用对象找到对应的 Binder 实体对象 binder_node
- 通过 binder 实体对象, 找到创建的 Server 进程
- 在 Server 进程找到最合适的空闲线程 target_thread 去处理这次 Binder 通信请求
- 创建 Binder 通信事务结构体 binder_transaction
- 服务端使用 t 描述
- 客户端使用 t_complete 描述
- 将客户端的数据拷贝到服务端的缓冲区
- 调用 binder_alloc_buf 函数, 分配一块内核缓冲区
- 将 Client 端数据拷贝到 Server 端的内核缓冲区, 这里即为 Binder 驱动通信中描述的一次拷贝
- 处理缓冲区数据中存在 Binder 本地对象的情况
- 若存在 Binder 本地对象
- 创建一个内核态的 Binder 实体对象 binder_node, 保存在 Client 端的缓存中
- 创建这个 binder_node 的 Binder 引用对象, 保存在 Server 端的缓存中
- 若存在 Binder 本地对象
- 将 Server 端的事务类型置为 BINDER_WORK_TRANSACTION, 添加 Server 的工作队列中
- Server 端有了任务, 那么阻塞在 binder_thread_read 上的线程就可被唤醒了
- 将 Client 端的事务类型置为 BINDER_WORK_TRANSACTION_COMPLETE, 添加到 Client 的工作队里中
- 唤醒 Server 端的 target_thread 去执行 BINDER_WORK_TRANSACTION
好的, binder_transaction 的 BC_TRANSACTION 可以说是非常复杂的, 从这里我们可以得知, Binder 本地对象只有在通过 Binder 驱动传输时, 才会在当前进程创建其内核态的描述 binder_node, 没有 binder_node 的 Binder 对象是没有意义的
好的, 从这里我们就可以看到 binder 驱动动态分配缓冲区的操作了, 当我们将数据用客户端拷贝到服务端的时候, 调用了 binder_alloc_buf 函数, 这便是一个动态分配缓冲区的过程, 下面我们看看他的具体操作
binder_alloc_buf 分配内核缓冲区
// kernel/goldfish/drivers/staging/android/binder.c
static struct binder_buffer *binder_alloc_buf(struct binder_proc *proc,
size_t data_size,
size_t offsets_size, int is_async)
{
struct rb_node *n = proc->free_buffers.rb_node;
struct binder_buffer *buffer;
size_t buffer_size;
struct rb_node *best_fit = NULL;
void *has_page_addr;
void *end_page_addr;
size_t size;
if (proc->vma == NULL) {
pr_err("%d: binder_alloc_buf, no vma\n",
proc->pid);
return NULL;
}
// 1. 计算请求分配内核缓冲区的大小
size = ALIGN(data_size, sizeof(void *)) +
ALIGN(offsets_size, sizeof(void *));
......
// 2. 使用最佳匹配算法在目标进程的空闲缓冲区红黑树中, 找到最合适的
while (n) {
buffer = rb_entry(n, struct binder_buffer, rb_node);
......
// 2.1 获取当前空闲缓冲区的大小
buffer_size = binder_buffer_size(proc, buffer);
// 2.2 若要拷贝数据的大小 < 当前空闲缓冲区
if (size < buffer_size) {
best_fit = n;
n = n->rb_left;
}
// 2.3 要拷贝的数据大小 > 空闲缓冲区
else if (size > buffer_size)
n = n->rb_right;
// 找到了最合适的
else {
best_fit = n;
break;
}
}
// 3. 传输的数据过大, Binder 驱动无法进行数据传输
// 最大的空闲缓冲区, 即我们调用 mmap 时初始化的
// 客户端为 1M - 8k
// 服务端为 128 kb
if (best_fit == NULL) {
......
return NULL;
}
// 4. 找到了比要拷贝数据大的空闲缓冲区
if (n == NULL) {
buffer = rb_entry(best_fit, struct binder_buffer, rb_node);
buffer_size = binder_buffer_size(proc, buffer);
}
......
// 5. 执行裁剪操作
// 5.1 记录原空闲缓冲区的结束地址所在的内存页面的起始地址
has_page_addr = (void *)(((uintptr_t)buffer->data + buffer_size) & PAGE_MASK);
// 5.2 计算裁剪后的缓冲区大小, 保存在 buffer_size 中
if (n == NULL) {
// 若要拷贝的大小 + 用于描述缓冲区的结构体大小 > 找到的空闲缓冲区 - 4 byte, 则不需要裁剪
if (size + sizeof(struct binder_buffer) + 4 >= buffer_size) {
buffer_size = size;
}
// 反之则裁剪为 size + sizeof(struct binder_buffer); 的大小
else {
buffer_size = size + sizeof(struct binder_buffer);
}
}
// 5.3 获取裁剪后的目标结束地址, 并且对其到当前内存页面边界
end_page_addr = (void *)PAGE_ALIGN((uintptr_t)buffer->data + buffer_size);
// 5.4 裁剪后对其到边界的地址 > 未裁剪前的页面存在数据的起始地址
// 则重置 end_page_addr 为 has_page_addr 防止边界越界
if (end_page_addr > has_page_addr)
end_page_addr = has_page_addr;
// 6. 为缓冲区分配物理页面
if (binder_update_page_range(proc, 1,
(void *)PAGE_ALIGN((uintptr_t)buffer->data), end_page_addr, NULL))
return NULL;
// 7. 将这块缓冲区从空闲红黑树中移除, 插入到已分配的红黑树中
rb_erase(best_fit, &proc->free_buffers);
buffer->free = 0;
// 插入到正在使用的红黑树中
binder_insert_allocated_buffer(proc, buffer);
// 8. 将裁剪后剩余的一块再次插入空闲红黑树
if (buffer_size != size) {
struct binder_buffer *new_buffer = (void *)buffer->data + size;
list_add(&new_buffer->entry, &buffer->entry);
new_buffer->free = 1;
binder_insert_free_buffer(proc, new_buffer);
}
......
// 返回这块缓冲区
return buffer;
}
分配内核缓冲区的代码可以说是非常有趣的, 其中的难点主要在于对内核缓冲的裁剪部分
- 不需要裁剪: 要拷贝的大小 + sizeof(binder_buffer) >= 空闲缓冲区大小 - 4 byte
- 需要裁剪: 要拷贝的大小 + sizeof(binder_buffer) < 空闲缓冲区大小 - 4 byte
- 裁剪为: 要拷贝的大小 + sizeof(binder_buffer)
有了分配了物理内存的内核缓冲区之后, binder 驱动就可以将客户端的数据拷贝到服务端的这个缓冲区中了
接下来我们需要关注的流程如下
- Server 端 target_thread 处理 BINDER_WORK_TRANSACTION
- Client 端处理 BINDER_WORK_TRANSACTION_COMPLETE
我们先看看 Client 对 BINDER_WORK_TRANSACTION_COMPLETE 的处理
五) 驱动处理 BINDER_WORK_TRANSACTION_COMPLETE 工作项
// kernel/goldfish/drivers/staging/android/binder.c
static int binder_ioctl_write_read(struct file *filp,
unsigned int cmd, unsigned long arg,
struct binder_thread *thread)
{
int ret = 0;
// 获取当前使用 Binder 驱动进程的描述
struct binder_proc *proc = filp->private_data;
unsigned int size = _IOC_SIZE(cmd);
// 1. 通过 copy_from_user, 拷贝用户空间传递过来的 binder_write_read 结构体
void __user *ubuf = (void __user *)arg;
struct binder_write_read bwr;
......
if (copy_from_user(&bwr, ubuf, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
// 2. 处理写操作
if (bwr.write_size > 0) {
ret = binder_thread_write(proc, thread,
bwr.write_buffer,
bwr.write_size,
&bwr.write_consumed);
......
}
// 3. 处理读操作
if (bwr.read_size > 0) {
ret = binder_thread_read(proc, thread, bwr.read_buffer,
bwr.read_size,
&bwr.read_consumed,
filp->f_flags & O_NONBLOCK);
......
}
......
// 4. 通过 copy_to_user, 将内核处理好的 binder_write_read 拷贝到用户空间
if (copy_to_user(ubuf, &bwr, sizeof(bwr))) {
ret = -EFAULT;
goto out;
}
out:
return ret;
}
通过上面的分析我们知道, binder_thread_write 执行完毕之后, 客户端的写操作已经执行完毕了
下面我们看看 binder_thread_read 如何处理, binder_thread_write 中写入的 BINDER_WORK_TRANSACTION_COMPLETE 工作项
// kernel/goldfish/drivers/staging/android/binder.c
static int binder_thread_read(.......) {
......
// 此时当前线程的工作队列有 BINDER_WORK_TRANSACTION_COMPLETE 工作项, 故不会阻塞
while(1) {
switch(w->type) {
......
case BINDER_WORK_TRANSACTION_COMPLETE: {
// 将 BR_TRANSACTION_COMPLETE 指令码写入内核缓冲区
cmd = BR_TRANSACTION_COMPLETE;
if (put_user_preempt_disabled(cmd, (uint32_t __user *)ptr))
return -EFAULT;
......
} break;
......
}
}
}
binder_thread_read 对 BINDER_WORK_TRANSACTION_COMPLETE 处理也非常简单, 它将 BR_TRANSACTION_COMPLETE 写入到 Client 端的内核缓冲区中
下面我们看看 Client 用户空间对 BR_TRANSACTION_COMPLETE 的操作
六) 用户态处理 BR_TRANSACTION_COMPLETE 工作项
我们上面有分析过, 用户空间的 waitForResponse 中可以通过 mIn 输入缓冲区读取到 binder 内核驱动传递过来的 BR_TRANSACTION_COMPLETE 指令
// frameworks/native/libs/binder/IPCThreadState.cpp
status_t IPCThreadState::waitForResponse(Parcel *reply, status_t *acquireResult)
{
uint32_t cmd;
int32_t err;
while (1) {
if ((err=talkWithDriver()) < NO_ERROR) break;
err = mIn.errorCheck();
if (err < NO_ERROR) break;
if (mIn.dataAvail() == 0) continue;
// 从输入缓冲区中读取, 是否有 Binder 驱动写入的数据
cmd = (uint32_t)mIn.readInt32();
// 主要查看 BR_TRANSACTION_COMPLETE 工作项
switch (cmd) {
case BR_TRANSACTION_COMPLETE:
// 若是没有返回值, 则会直接 finish, 若存在返回值, 会继续调用 talkWithDriver 等待返回值的到来
if (!reply && !acquireResult) goto finish;
break;
......
}
finish:
if (err != NO_ERROR) {
if (acquireResult) *acquireResult = err;
if (reply) reply->setError(err);
mLastError = err;
}
return err;
}
可以看到 waitForResponse 的 BR_TRANSACTION_COMPLETE 操作很简单
- 若无返回值, 则直接结束 binder 通信
- 若存在返回值, 则继续循环等待目标进程将上次发出的进程间通信请求返回回来
所以, 接下来的重头戏便是 Server 端目标线程对 Binder 驱动发出的 BINDER_WORK_TRANSACTION 工作项的处理了
二. Server 端响应 Client 请求
由前面可知, BINDER_WORK_TRANSACTION 会将工作项添加到目标进程的 todo 队列中
通过 ServiceManager 进程启动的章节可知, 当线程的有任务时 ServiceManager 阻塞在 binder_thread_read 的线程将会被唤醒, 下面我们看看它对 BINDER_WORK_TRANSACTION 的处理
一) 驱动处理 BINDER_WORK_TRANSACTION 工作项
// kernel/goldfish/drivers/staging/android/binder.c
static int binder_thread_read(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed, int non_block)
{
void __user *buffer = (void __user *)(uintptr_t)binder_buffer;
void __user *ptr = buffer + *consumed;
void __user *end = buffer + size;
......// 有任务, 阻塞唤醒
// 循环从其读取器工作项数据
while (1) {
uint32_t cmd;
struct binder_transaction_data tr;
struct binder_work *w;
struct binder_transaction *t = NULL;
// 1. 从其线程/进程的 todo 队列中获取工作项, 并且将数据存入 binder_work 结构体对象中
if (!list_empty(&thread->todo)) {
w = list_first_entry(&thread->todo, struct binder_work,
entry);
} else if (!list_empty(&proc->todo) && wait_for_proc_work) {
w = list_first_entry(&proc->todo, struct binder_work,
entry);
} else {
......
break;
}
switch (w->type) {
// 我们主要关注对 BINDER_WORK_TRANSACTION 的处理
case BINDER_WORK_TRANSACTION: {
// 2. 将 binder_work 转为事务的描述结构体 binder_transaction
t = container_of(w, struct binder_transaction, work);
} break;
......
// 3. 将 binder_transaction 中的数据写入 binder_transaction_data 中
if (t->buffer->target_node) {// target_node 指 Server 端的 Binder 实体对象
// 3.1 将 binder 本地对象的信息复制到 tr 中
struct binder_node *target_node = t->buffer->target_node;
// 通过这个 tr.target.ptr 就可以找到用户空间的 BBinder 了
tr.target.ptr = target_node->ptr;
......
// 指令码为 BR_TRANSACTION
cmd = BR_TRANSACTION;
} else {
......
}
.......
// 4. 记录 Client 端拷贝到 Server 缓冲区的首地址
tr.data.ptr.buffer = (binder_uintptr_t)(
(uintptr_t)t->buffer->data +
proc->user_buffer_offset);
tr.data.ptr.offsets = tr.data.ptr.buffer +
ALIGN(t->buffer->data_size,
sizeof(void *));
// 5. 将指令码 BR_TRANSACTION 拷贝到 read 缓冲区
if (put_user(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
// 6. 将 binder_transaction_data 拷贝到read 缓冲区
if (copy_to_user(ptr, &tr, sizeof(tr)))
return -EFAULT;
ptr += sizeof(tr);
.......
// 这个工作项已经被处理了, 从链表中删除
list_del(&t->work.entry);
......
break;
}
return 0;
}
可见目标线程被唤醒之后他在 binder 驱动中做了如下的事情
- 从目标线程的 todo 队列中获取工作项, 并且将数据存入 binder_work 结构体对象中
- 将 binder_work 转为事务描述结构体 binder_transaction
- 将 binder_transaction 中的数据写入 binder_transaction_data 中
- 记录 Client 拷贝到 Server 的内核缓冲区的数据对应在用户空间的首地址
- 将指令码 BR_TRANSACTION 拷贝到 read 缓冲区中
- 将 binder_transaction_data 拷贝到 read 缓冲区中
好的, binder_transaction_data 记录了 Client 端拷贝到 Server 端的数据在用户空间的首地址之后, Server 的用户空间就可以很方便访问物理内存中的数据了
下面我们看看用户态对 BR_TRANSACTION 指令的处理
二) 用户态处理 BR_TRANSACTION 指令
通过 ServiceManager 进程启动篇的分析, 我们知道从内核读取数据成功后, 会调用 binder_parse 方法来处理从 Binder 驱动程序中接收到的返回协议, 下面我们就看看 binder_parse 对 BR_TRANSACTION 的处理
// frameworks/base/cmds/servicemanager/binder.c
int binder_parse(struct binder_state *bs, struct binder_io *bio,
uintptr_t ptr, size_t size, binder_handler func)
{
int r = 1;
uintptr_t end = ptr + (uintptr_t) size;
while (ptr < end) {
// 1. 读取缓冲区的指令码
uint32_t cmd = *(uint32_t *) ptr;
ptr += sizeof(uint32_t);
switch(cmd) {
......
// 这里主要关注 BR_TRANSACTION 协议
case BR_TRANSACTION: {
// 2. 获取通信数据 binder_transaction_data
struct binder_transaction_data *txn = (struct binder_transaction_data *) ptr;
......
if (func) {
unsigned rdata[256/4];
struct binder_io msg; // Client 端通过 Binder 驱动传递过来的数据
struct binder_io reply; // 将通信结果写入 reply 中以便于传给 Binder 驱动, 进而返回源进程
int res;
// 初始化 reply 和 rdata
bio_init(&reply, rdata, sizeof(rdata), 4);
// 3. 获取 Client 端通过 Binder 驱动传递过来的实参
bio_init_from_txn(&msg, txn);
// 4. 调用 func 函数指针, 将结果写入 reply
res = func(bs, txn, &msg, &reply);
......
// 5. 通过 Binder 驱动将数据回传给 Client 端
binder_send_reply(bs, &reply, txn->data.ptr.buffer, res);
}
ptr += sizeof(*txn);
break;
}
}
}
}
binder_parse 中对于 BR_TRANSACTION 的操作还是非常清晰的
- 读取缓冲区的指令码
- 获取通信数据 binder_transaction_data
- 获取 Client 端通过 Binder 驱动传递过来的实参 binder_io msg
- 调用 func 函数指针, 将结果写入 binder_io reply
- 通过 Binder 驱动将数据回传给 Client 端
1. 执行 func 函数
在 ServiceManager 中, func 这个函数指针, 指代 svcmgr_handler 这个函数
// frameworks/base/cmds/servicemanager/service_manager.c
int svcmgr_handler(struct binder_state *bs,
struct binder_transaction_data *txn,
struct binder_io *msg,
struct binder_io *reply)
{
......
// 验证接口名称的描述
strict_policy = bio_get_uint32(msg);
s = bio_get_string16(msg, &len);
if (s == NULL) {
return -1;
}
// 执行对应的方法
switch(txn->code) {
case SVC_MGR_ADD_SERVICE:
// 获取一个要注册服务的名称 (如"ActivityManagerService")
s = bio_get_string16(msg, &len);
if (s == NULL) {
return -1;
}
// 从 msg 中取出要注册的服务 Binder 引用对象 binder_ref 的句柄值
handle = bio_get_ref(msg);
allow_isolated = bio_get_uint32(msg) ? 1 : 0;
// 执行添加服务的操作
if (do_add_service(bs, s, len, handle, txn->sender_euid,
allow_isolated, txn->sender_pid))
return -1;
break;
default:
ALOGE("unknown code %d\n", txn->code);
return -1;
}
// 调用这个函数, 将成功代码 0 写入到 binder 结构体 reply 中
bio_put_uint32(reply, 0);
return 0;
}
可以看到一个非常重要的函数 do_add_service 这个函数真正执行了服务的添加过程
// frameworks/base/cmds/servicemanager/service_manager.c
int do_add_service(struct binder_state *bs,
const uint16_t *s, size_t len,
uint32_t handle, uid_t uid, int allow_isolated,
pid_t spid)
{
struct svcinfo *si;
if (!handle || (len == 0) || (len > 127))
return -1;
// 判断 uid 所指代的源进程, 是否有资格进行注册操作
if (!svc_can_register(s, len, spid, uid)) {
return -1;
}
// 判断 si 服务是否已经注册了
si = find_svc(s, len);
if (si) {
......
} else {
// 创建一个 svcinfo 并且链入 svclist 中
si = malloc(sizeof(*si) + (len + 1) * sizeof(uint16_t));
si->handle = handle;
si->len = len;
memcpy(si->name, s, (len + 1) * sizeof(uint16_t));
si->name[len] = '\0';
si->death.func = (void*) svcinfo_death;
si->death.ptr = si;
si->allow_isolated = allow_isolated;
si->next = svclist;
svclist = si;
}
binder_acquire(bs, handle);
// 绑定死亡通知
binder_link_to_death(bs, handle, &si->death);
return 0;
}
至此就成功的将一个 Service 组件注册到 ServiceManager 中了
2. 将 reply 通过 Binder 驱动回传给 Client 端
// frameworks/base/cmds/servicemanager/service_manager.c
void binder_send_reply(struct binder_state *bs,
struct binder_io *reply,
binder_uintptr_t buffer_to_free,
int status)
{
struct {
uint32_t cmd_free;
binder_uintptr_t buffer;
uint32_t cmd_reply;
struct binder_transaction_data txn;
} __attribute__((packed)) data;
// 1. 写入指令码 BC_FREE_BUFFER 到 cmd_free
data.cmd_free = BC_FREE_BUFFER;
data.buffer = buffer_to_free;
// 2. 写入指令码 BC_REPLY 到 cmd_reply
data.cmd_reply = BC_REPLY;
data.txn.target.ptr = 0;
data.txn.cookie = 0;
data.txn.code = 0;
// 3. 将相关数据封装到 binder_transaction_data 中
if (status) {
data.txn.flags = TF_STATUS_CODE;
data.txn.data_size = sizeof(int);
data.txn.offsets_size = 0;
data.txn.data.ptr.buffer = (uintptr_t)&status;
data.txn.data.ptr.offsets = 0;
} else {
data.txn.flags = 0;
data.txn.data_size = reply->data - reply->data0;
data.txn.offsets_size = ((char*) reply->offs) - ((char*) reply->offs0);
data.txn.data.ptr.buffer = (uintptr_t)reply->data0;
data.txn.data.ptr.offsets = (uintptr_t)reply->offs0;
}
// 与 Client 端用户态与 Binder 驱动通信类似, 这里最终会调用 ioctl 将数据发送给 Binder 驱动
binder_write(bs, &data, sizeof(data));
}
binder_send_reply 中做的操作也比较清晰
- 写入指令码 BC_FREE_BUFFER 到 cmd_free
- 表示 Server 端处理完毕, 可以释放这块内核缓冲区
- 写入指令码 BC_REPLY 到 cmd_reply
- 表示请求 Binder 驱动处理 Server 端的回执数据
- 最终调用了 binder_write 函数
- 其内部调用 ioctl() 函数将 BC_FREE_BUFFER/BC_REPLY 发送给 binder 驱动程序
关于 ioctl 这里就不再赘述了, 接下来看看 Binder 驱动如何处理 BC_FREE_BUFFER/BC_REPLY 这些指令的
三) 驱动处理 BC_FREE_BUFFER 指令
// kernel/goldfish/drivers/staging/android/binder.c
static int binder_thread_write(struct binder_proc *proc,
struct binder_thread *thread,binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed)
{
......
while (ptr < end && thread->return_error == BR_OK) {
// 获取从用户空间传递过来的指令码保存在 cmd 中, 由上面可知, cmd 为 BC_TRANSACTION
if (get_user_preempt_disabled(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
......
switch(cmd) {
......
// 处理 BC_FREE_BUFFER 协议码
case BC_FREE_BUFFER: {
binder_uintptr_t data_ptr;
struct binder_buffer *buffer;
// 从用户空间中得到要释放的内核缓冲区的地址, 存放到 data_ptr 中
if (get_user_preempt_disabled(data_ptr, (binder_uintptr_t __user *)ptr))
return -EFAULT;
ptr += sizeof(binder_uintptr_t);
// 获取缓冲区
buffer = binder_buffer_lookup(proc, data_ptr);
if (buffer == NULL) {
break;
}
// 判断是否允许释放
if (!buffer->allow_user_free) {
break;
}
// 说明内核缓冲区分配给 transaction 使用的
if (buffer->transaction) {
buffer->transaction->buffer = NULL;
buffer->transaction = NULL;
}
if (buffer->async_transaction && buffer->target_node) {
BUG_ON(!buffer->target_node->has_async_transaction);
if (list_empty(&buffer->target_node->async_todo))
buffer->target_node->has_async_transaction = 0;
else
list_move_tail(buffer->target_node->async_todo.next, &thread->todo);
}
// 减少相关的引用计数
binder_transaction_buffer_release(proc, buffer, NULL);\
// 释放内核缓冲区 buffer
binder_free_buf(proc, buffer);
break;
}
......
}
可以看到 binder_thread_write 中对于 BC_FREE_BUFFER 协议码的处理, 主要是释放通信过程给目标进程分配的内核缓冲区, 减少相关的引用计数
接下来看看 binder_thread_write 对 BC_REPLY 的处理
四) 驱动处理 BC_REPLY 指令
static int binder_thread_write(struct binder_proc *proc,
struct binder_thread *thread,
binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed)
{
......
// 处理 BC_TRANSACTION/BC_REPLY
case BC_TRANSACTION:
case BC_REPLY: {
// 从用户空间拷贝参数数据到 binder_transaction_data 中
struct binder_transaction_data tr;
if (copy_from_user_preempt_disabled(&tr, ptr, sizeof(tr)))
return -EFAULT;
ptr += sizeof(tr);
// 进行指令码的处理操作
binder_transaction(proc, thread, &tr,
cmd == BC_REPLY, 0);
break;
}
......
}
}
static void binder_transaction(struct binder_proc *proc,
struct binder_thread *thread,
struct binder_transaction_data *tr, int reply,
binder_size_t extra_buffers_size)
{
......
if (reply) {
// 处理 BC_REPLY 指令
// 找寻目标线程(即 Client 端的线程)
in_reply_to = thread->transaction_stack;
if (in_reply_to == NULL) {
binder_user_error("%d:%d got reply transaction with no transaction stack\n",
proc->pid, thread->pid);
return_error = BR_FAILED_REPLY;
goto err_empty_call_stack;
}
// 恢复目标线程的优先级
binder_set_nice(in_reply_to->saved_priority);
if (in_reply_to->to_thread != thread) {
......
return_error = BR_FAILED_REPLY;
in_reply_to = NULL;
goto err_bad_call_stack;
}
// 将要处理的事务, 添加到线程栈的顶端
thread->transaction_stack = in_reply_to->to_parent;
target_thread = in_reply_to->from;
if (target_thread == NULL) {
return_error = BR_DEAD_REPLY;
goto err_dead_binder;
}
if (target_thread->transaction_stack != in_reply_to) {
return_error = BR_FAILED_REPLY;
in_reply_to = NULL;
target_thread = NULL;
goto err_dead_binder;
}
target_proc = target_thread->proc;
} else {// 处理 BC_TRANSACTION 指令, 前面已经分析过了
......
}
// ....... 与分析 BC_TRANSACTION 后续一致
}
可以看到 Binder 驱动对于 BC_REPLY 比较简单, 除了 BC_REPLY 中的操作与 BC_TRANSACTION 有所不同, 后续的操作是一致的, 毕竟调用的是同一个方法
最终会封装成两个工作项 BINDER_WORK_TRANSACTION 和 BINDER_WORK_TRANSACTION_COMPLETE 分别发送给目标进程和源进程 (这里的目标进程为Client 端, 源进程为 Server 端了, 因为本次发起 Binder 驱动通信的为 Server 端)
- 源进程接收到 BINDER_WORK_TRANSACTION_COMPLETE 之后, 就彻底的结束这次的 Binder 通信了, 这里不再赘述
接下来看看 Client 端如何处理 BINDER_WORK_TRANSACTION 工作项
三. Client 读取 Server 返回值
一) 驱动处理 BINDER_WORK_TRANSACTION 工作项
上面我们提到当 Client 将数据发送成功之后, 便会在 waitForResponse 的 while 循环中等待返回值的到来, 也就是说它同样会阻塞在 binder_thread_read 中
// kernel/goldfish/drivers/staging/android/binder.c
static int binder_thread_write(struct binder_proc *proc,
struct binder_thread *thread,binder_uintptr_t binder_buffer, size_t size,
binder_size_t *consumed)
{
......
// 循环从其读取器工作项数据
while (1) {
uint32_t cmd;
struct binder_transaction_data tr;
struct binder_work *w;
struct binder_transaction *t = NULL;
......
// 处理工作项中对应的指令码
switch (w->type) {
// 我们主要关注对 BINDER_WORK_TRANSACTION 的处理
case BINDER_WORK_TRANSACTION: {
t = container_of(w, struct binder_transaction, work);
} break;
......
// 1. 将 binder_transaction 中的数据存入 binder_transaction_data 中, 以便后续可以传输到用户空间
if (t->buffer->target_node) {
......// 上面已经分析过了
} else {
// target_node 为 NULL, 则指定协议码 BR_REPLY
tr.target.ptr = 0;
tr.cookie = 0;
cmd = BR_REPLY;
}
.......
// 2. 将协议码内核缓冲区
if (put_user_preempt_disabled(cmd, (uint32_t __user *)ptr))
return -EFAULT;
ptr += sizeof(uint32_t);
// 3. 将 binder_transaction_data 写到内核缓冲区
if (copy_to_user_preempt_disabled(ptr, &tr, sizeof(tr)))
return -EFAULT;
ptr += sizeof(tr);
.......
// 这个工作项已经被处理了, 从链表中删除
list_del(&t->work.entry);
t->buffer->allow_user_free = 1;
......
break;
}
return 0;
}
其代码与 ServiceManager 阻塞在 binder_thread_read 是一致的, 这里就不再赘述了, 我们主要看看用户态对 BR_REPLY 的处理
二) 用户态处理 BR_REPLY
status_t IPCThreadState::waitForResponse(Parcel *reply, status_t *acquireResult)
{
uint32_t cmd;
int32_t err;
while (1) {
if ((err=talkWithDriver()) < NO_ERROR) break;
......
// 从输入缓冲区中读取, 是否有 Binder 驱动写入的数据
cmd = (uint32_t)mIn.readInt32();
// 主要查看 BR_TRANSACTION_COMPLETE 指令码
switch (cmd) {
case BR_REPLY:
{
// 从用户缓冲区获取 Binder 驱动写入的数据
binder_transaction_data tr;
err = mIn.read(&tr, sizeof(tr));
if (err != NO_ERROR) goto finish;
if (reply) {
// 表示该线程发送的进程间通信请求已经被处理了
if ((tr.flags & TF_STATUS_CODE) == 0) {
// 这个方法将 Binder 驱动传递过来的数据写入 Parcel 的 reply 中
reply->ipcSetDataReference(
reinterpret_cast<const uint8_t*>(tr.data.ptr.buffer),
tr.data_size,
reinterpret_cast<const binder_size_t*>(tr.data.ptr.offsets),
tr.offsets_size/sizeof(binder_size_t),
freeBuffer, this);
} else {
......
}
} else {
......
}
}
// 跳出循环, 即 waitForResponse 等待进程通信的结果的操作已经结束了
goto finish;
......
}
finish:
......
return err;
}
可以看到 Client 端用户空间对 BR_REPLY 的操作也非常清晰
- 从内核缓冲区中获取 binder_transaction_data 结构体 tr
- 将 tr 中的数据写入 Parcel 的 reply 中
- 跳出循环, 即 waitForResponse 函数执行结束, 本次 Binder 进程间通信结束
好的, 至此 Client 的用户态便接收到了 Server 返回的数据, 这次通过 Binder 的通信便结束了
总结
Binder 驱动跨进程通信, 是十分复杂的, 其指令交互如下
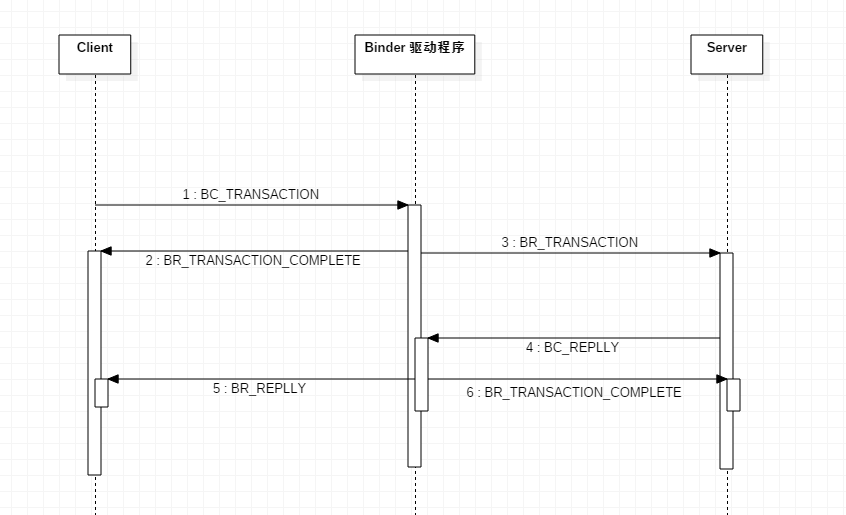
- Client 端发送请求到 Server 端
- 用户态将请求数据封装成 Parcel, 写入内核缓存区, 指令为 BC_TRANSACTION
- 通过 ioctl 通知 Binder 驱动处理 BC_TRANSACTION
- Binder 驱动处理 BC_TRANSACTION 指令
- 将数据拷贝给 Server 进程的内核缓存区
- 这是一次深拷贝
- 判断 Client 发送的数据中是否存在 Binder 本地对象
- 若存在, 则创建其 Kernel 对应的 binder_node 结构体, 这样其他进程才能够通过 Binder 驱动找到它
- 返回工作项 BR_TRANSACTION_COMPLETE 到 Client 端
- 用户态执行 BR_TRANSACTION_COMPLETE 工作项
- 返回工作项 BINDER_WORK_TRANSACTION 到 Server 端
- 唤醒阻塞在 binder_thread_read 上的线程执行任务
- 将数据拷贝给 Server 进程的内核缓存区
- 用户态将请求数据封装成 Parcel, 写入内核缓存区, 指令为 BC_TRANSACTION
- Server 端执行请求返回给 Client 端
- Binder 驱动处理 BINDER_WORK_TRANSACTION 工作项
- 将 Client 拷贝到 Server 缓冲区的数据地址 记录在 binder_transaction_data 中
- 这是一次浅拷贝
- 将 binder_transaction_data 和 指令码 BR_TRANSACTION 写到与用户态交互的内核缓冲区中
- 将 Client 拷贝到 Server 缓冲区的数据地址 记录在 binder_transaction_data 中
- 用户态处理 BR_TRANSACTION 指令
- 从缓冲区中读取 Client 通过 Binder 驱动发送过来的数据
- 执行请求, 并将请求执行结果封装成 Parcel, 写入内核缓存区, 指令为 BC_FREE_BUFFER/BC_REPLY
- 通过 ioctl 通知 Binder 驱动处理 BC_FREE_BUFFER/BC_REPLY
- Binder 驱动处理 BC_FREE_BUFFER 指令
- 释放相关缓冲区, 减少引用计数
- Binder 驱动处理 BC_REPLY 指令
- 将数据拷贝到 Client 的内核缓存区
- 返回工作项 BR_TRANSACTION_COMPLETE 到 Server 端
- 用户态处理 BR_TRANSACTION_COMPLETE 指令
- 返回工作项 BR_REPLY 到 Client 端
- 唤醒阻塞在 binder_thread_read 上线程执行任务
- Binder 驱动处理 BINDER_WORK_TRANSACTION 工作项
- Client 端接收 Server 端数据
- Binder 驱动处理 BINDER_WORK_TRANSACTION
- 将 BR_REPLY 和回执数据写入到内核缓冲区
- 用户态处理 BR_REPLY 指令, 从内核缓冲区中读取参数
- Binder 驱动处理 BINDER_WORK_TRANSACTION
至此一次完整的 Binder 通信就结束了, 这里我们便了解到几点非常重要的知识
- binder 驱动的缓冲区的动态分配是在跨进程数据拷贝时, 通过 binder_alloc_buf 实现的
- 使用完成之后, 会通过 BC_FREE_BUFFER 释放这块缓冲区
- Binder 本地对象创建完成之后, 需要通过 Parcel 发送给 Binder 驱动, 才有机会创建 binder_node 对象, 缓存在 binder_proc 中, 也就是说我们仅仅 new 一个 Binder 是不具有跨进程通信功能的
- ServiceManager 虽然是上下文管理者, 主要管理的是系统服务提供的 Binder 代理对象, 我们自己创建的 Service 通过 onBind 发布的 Binder 对象, ServiceManager 是不负责的管理的
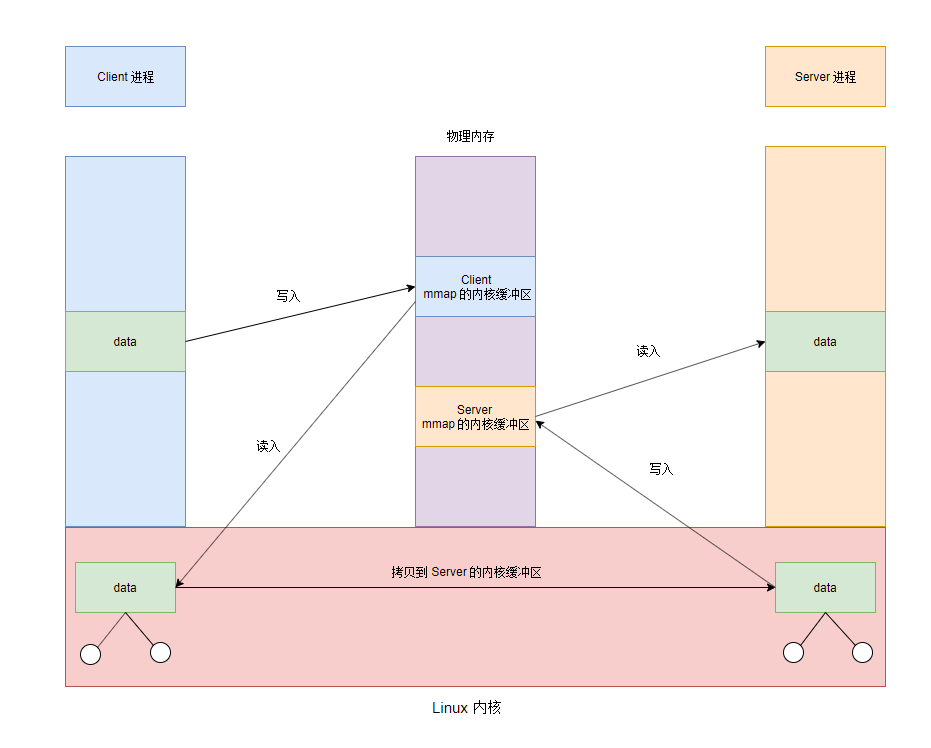
- 网上常说的 Binder 驱动一次拷贝, 是指两个进程之间的拷贝, 并不是用户空间到内核空间的拷贝, 因此 Binder 驱动跨进程通信并非是跨进程共享内存
流程图
从宏观上来看, 其流程图如下