前言
Android 系统不如 IOS 流畅的问题, 一致被广大用户诟病, Google 为此也下了很多的功夫, 各个 Android 版本的渲染变更如下
| Android 版本 | 渲染变更 |
|---|---|
| Android 3.0 阶段 | 开始支持硬件加速 |
| Android 4.0 阶段 | 默认开启硬件加速 |
| Android 4.1 阶段 | 1. 引入了 VSYNC 垂直同步信号 2. Triple Buffering 三缓冲机制 |
| Android 4.2 阶段 | 开发者选项中引入了过度渲染监控工具 |
| Android 5.0 阶段 | 1. 引入了 RenderNode 来保存 View 的绘制动作 DisplayList 2. 引入了 RenderThread, 所有的 GL 命令都在 RenderThread 中进行, 减轻了 UI 线程的工作量 |
| Android 7.0 阶段 | 引入了 Vulkan 的硬件渲染引擎 |
可以看到 Android 4.0 之后, 就已经默认开启硬件加速了, 5.0 之后更是引入了 RenderNode 和 RenderThread 来提升渲染能力, 关于软件渲染的相关知识请点击这里回顾
通过对 OpenCV 和 OpenGL 的学习, 让我们对图像图形学有了一定的了解, 这里再回过头来看看 Android 的图形架构的硬件绘制部分就比较轻松了, 这里我们以 Android 9.0 源码为例, 揭开 5.0 阶段之后硬件渲染的机制, 以及 RenderNode 和 RenderThread 的神秘面纱
一. ThreadedRenderer 的创建
关于硬件绘制的开启, 这需要从 ViewRootImpl 的创建说起
ViewRootImpl 是用于管理 View 树与其依附 Window 的一个媒介, 当我们调用 WindowManager.addView 时便会创建一个 ViewRootImpl 来管理即将添加到 Window 中的 View
public final class WindowManagerGlobal {
public void addView(View view, ViewGroup.LayoutParams params,
Display display, Window parentWindow) {
ViewRootImpl root;
synchronized (mLock) {
// 创建了 ViewRootImpl 的实例
root = new ViewRootImpl(view.getContext(), display);
view.setLayoutParams(wparams);
// 添加到缓存中
mViews.add(view);
mRoots.add(root);
mParams.add(wparams);
try {
// 将要添加的视图添加到 ViewRootImpl 中
root.setView(view, wparams, panelParentView);
} catch (RuntimeException e) {
......
}
}
}
}
public final class ViewRootImpl implements ViewParent,
View.AttachInfo.Callbacks, ThreadedRenderer.DrawCallbacks {
final View.AttachInfo mAttachInfo;
public ViewRootImpl(Context context, Display display) {
......
// 构建了一个 View.AttachInfo 用于描述这个 View 树与其 Window 的依附关系
mAttachInfo = new View.AttachInfo(mWindowSession, mWindow, display, this, mHandler, this,
context);
......
}
public void setView(View view, WindowManager.LayoutParams attrs, View panelParentView) {
synchronized (this) {
if (mView == null) {
// DecorView 实现了 RootViewSurfaceTaker 接口
if (view instanceof RootViewSurfaceTaker) {
// 尝试获取 callback
mSurfaceHolderCallback =
((RootViewSurfaceTaker)view).willYouTakeTheSurface();
// callback 不为 null, 则创建 SurfaceHolder
if (mSurfaceHolderCallback != null) {
mSurfaceHolder = new TakenSurfaceHolder();
mSurfaceHolder.setFormat(PixelFormat.UNKNOWN);
mSurfaceHolder.addCallback(mSurfaceHolderCallback);
}
}
// 若 mSurfaceHolder 为 null, 也就是说 DecorView.willYouTakeTheSurface 为 null, 则开启硬件加速
if (mSurfaceHolder == null) {
enableHardwareAcceleration(attrs);
}
}
}
}
private void enableHardwareAcceleration(WindowManager.LayoutParams attrs) {
mAttachInfo.mHardwareAccelerated = false;
mAttachInfo.mHardwareAccelerationRequested = false;
......
final boolean hardwareAccelerated =
(attrs.flags & WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED) != 0;
if (hardwareAccelerated) {
......
if (fakeHwAccelerated) {
......
} else if (!ThreadedRenderer.sRendererDisabled
|| (ThreadedRenderer.sSystemRendererDisabled && forceHwAccelerated)) {
......
// 创建硬件加速的渲染器
mAttachInfo.mThreadedRenderer = ThreadedRenderer.create(mContext, translucent,
attrs.getTitle().toString());
mAttachInfo.mThreadedRenderer.setWideGamut(wideGamut);
if (mAttachInfo.mThreadedRenderer != null) {
mAttachInfo.mHardwareAccelerated =
mAttachInfo.mHardwareAccelerationRequested = true;
}
}
}
}
}
好的, 这个硬件加速渲染器是通过 WindowManager.LayoutParams.FLAG_HARDWARE_ACCELERATED 来决定的, 最终会调用 ThreadedRenderer.create 来创建一个 ThreadedRenderer 对象
他会给 mAttachInfo 的 mThreadedRenderer 属性创建一个渲染器线程的描述, 下面看看 ThreadedRenderer.create 函数的实现
public final class ThreadedRenderer {
public static ThreadedRenderer create(Context context, boolean translucent, String name) {
ThreadedRenderer renderer = null;
if (isAvailable()) {
// 创建 ThreadedRenderer 对象
renderer = new ThreadedRenderer(context, translucent, name);
}
return renderer;
}
private long mNativeProxy; // 描述渲染代理对象 Native 句柄值
private RenderNode mRootNode;// 描述当前窗体的根渲染结点
ThreadedRenderer(Context context, boolean translucent, String name) {
......
// 调用 nCreateRootRenderNode 构建了一个 Native 对象, 来描述窗体的跟渲染结点
long rootNodePtr = nCreateRootRenderNode();
// 包装成 Java 的 RenderNode
mRootNode = RenderNode.adopt(rootNodePtr);
// 创建了一个 RenderProxy 渲染代理对象
mNativeProxy = nCreateProxy(translucent, rootNodePtr);
}
}
public class RenderNode {
public static RenderNode adopt(long nativePtr) {
return new RenderNode(nativePtr);
}
}
ThreadedRenderer 的构造函数中, 有两个非常重要的操作
- 通过 nCreateRootRenderNode 创建 Native 层的根渲染结点
- 通过 nCreateProxy 创建渲染代理对象
下面我们一一分析
一) 创建 Native 层的根渲染结点
// frameworks/base/core/jni/android_view_ThreadedRenderer.cpp
static jlong android_view_ThreadedRenderer_createRootRenderNode(JNIEnv* env, jobject clazz) {
// 创建了一个 RootRenderNode 对象
RootRenderNode* node = new RootRenderNode(env);
node->incStrong(0);
node->setName("RootRenderNode");
return reinterpret_cast<jlong>(node);
}
class RootRenderNode : public RenderNode, ErrorHandler {
public:
explicit RootRenderNode(JNIEnv* env) : RenderNode() {
// 保存了主线程的 Looper (Native)
mLooper = Looper::getForThread();
env->GetJavaVM(&mVm);
}
}
// frameworks/base/libs/hwui/RenderNode.cpp
RenderNode::RenderNode()
: mDirtyPropertyFields(0)
, mNeedsDisplayListSync(false)
, mDisplayList(nullptr)
, mStagingDisplayList(nullptr)
, mAnimatorManager(*this)
, mParentCount(0) {}
更渲染结点的创建流程比较简单, 即创建了一个 Native 层的 RootRenderNode 对象, 然后将其句柄值返回到 Java 层
接下来看看渲染代理对象的创建
二) 创建渲染代理对象
// frameworks/base/core/jni/android_view_ThreadedRenderer.cpp
static jlong android_view_ThreadedRenderer_createProxy(JNIEnv* env, jobject clazz,
jboolean translucent, jlong rootRenderNodePtr) {
RootRenderNode* rootRenderNode = reinterpret_cast<RootRenderNode*>(rootRenderNodePtr);
// 使用 RootRenderNode 创建了一个 ContextFactoryImpl
ContextFactoryImpl factory(rootRenderNode);
// 创建了一个渲染的代理对象 RenderProxy
return (jlong) new RenderProxy(translucent, rootRenderNode, &factory);
}
RenderProxy::RenderProxy(bool translucent, RenderNode* rootRenderNode,
IContextFactory* contextFactory)
// 1. 获取 RenderThread 对象
: mRenderThread(RenderThread::getInstance())
, mContext(nullptr) {
// 2, 可以看到这里创建了一个 CanvasContext
mContext = mRenderThread.queue().runSync([&]() -> CanvasContext* {
return CanvasContext::create(mRenderThread, translucent, rootRenderNode, contextFactory);
});
mDrawFrameTask.setContext(&mRenderThread, mContext, rootRenderNode);
}
从 RenderProxy 对象的创建中我们可以看到非常重要的信息, 它内部持有了 mRenderThread 的渲染子线程, 并且创建一个了 CanvasContext 描述实现渲染操作的上下文
从这里了我们就可以猜测, 最终我们的渲染动作会交由 RenderProxy 的 mRenderThread 线程来执行的, 以此来减轻 UI 线程的工作压力, 下面我们看看 CanvasContext 的创建过程
CanvasContext 的创建
// frameworks/base/libs/hwui/renderthread/CanvasContext.cpp
CanvasContext* CanvasContext::create(RenderThread& thread, bool translucent,
RenderNode* rootRenderNode, IContextFactory* contextFactory) {
auto renderType = Properties::getRenderPipelineType();
switch (renderType) {
case RenderPipelineType::OpenGL:
// 使用 OpenGL 的渲染管线
return new CanvasContext(thread, translucent, rootRenderNode, contextFactory,
std::make_unique<OpenGLPipeline>(thread));
case RenderPipelineType::SkiaGL:
// 使用 SkiaOpenGLPipeline 的渲染管线
return new CanvasContext(thread, translucent, rootRenderNode, contextFactory,
std::make_unique<skiapipeline::SkiaOpenGLPipeline>(thread));
case RenderPipelineType::SkiaVulkan:
// 使用 SkiaVulkanPipeline 的渲染管线
return new CanvasContext(thread, translucent, rootRenderNode, contextFactory,
std::make_unique<skiapipeline::SkiaVulkanPipeline>(thread));
default:
LOG_ALWAYS_FATAL("canvas context type %d not supported", (int32_t)renderType);
break;
}
return nullptr;
}
CanvasContext::CanvasContext(RenderThread& thread, bool translucent, RenderNode* rootRenderNode,
IContextFactory* contextFactory,
std::unique_ptr<IRenderPipeline> renderPipeline)
: mRenderThread(thread)
, mGenerationID(0)
, mOpaque(!translucent)
, mAnimationContext(contextFactory->createAnimationContext(mRenderThread.timeLord()))
, mJankTracker(&thread.globalProfileData(), thread.mainDisplayInfo())
, mProfiler(mJankTracker.frames())
, mContentDrawBounds(0, 0, 0, 0)
, mRenderPipeline(std::move(renderPipeline)) {
// 标记为渲染根结点
rootRenderNode->makeRoot();
mRenderNodes.emplace_back(rootRenderNode);
// 注册该对象为渲染的上下文
mRenderThread.renderState().registerCanvasContext(this);
mProfiler.setDensity(mRenderThread.mainDisplayInfo().density);
}
从这里可以看到, CanvasContext 的工厂方法的 create 中根据不同的 Type, 注入了不同的渲染管线的实现
通过 API 的方式对上层提供服务, 很好的屏蔽了实现的细节, 也是策略设计模式的一种体现, 其中还可以看到 7.0 之后支持的 Vulkan 渲染管线的实现
关于 Vlukan 的硬件渲染引擎笔者不是很了解, 想了解更多可以 查看这篇博文, 本篇我们主要关注 OpenGL 硬件渲染引擎的实现
三) 回顾
到这里 ThreadRenderer 的创建便完成了, 这里回顾一下各个对象的依赖关系
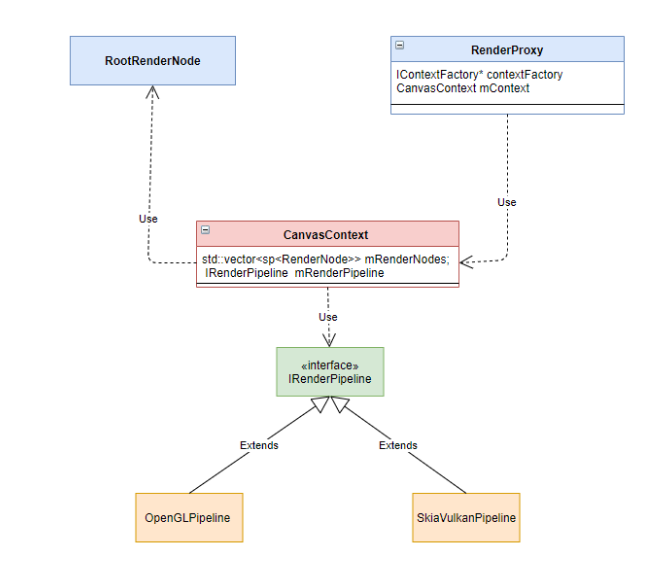
在 ThreadRenderer 创建的过程中, 我们并没有看到它与 Surface 进行绑定的过程, 这意味着渲染之后的数据是无法推送给 SurfaceFlinger 进行图像合成, 更别提展示到屏幕上了
因此一定还存在一个与 Surface 绑定的过程, 这就是 ThreadedRenderer 的初始化, 下面看看它的具体实现
二. ThreadedRenderer 的初始化
public final class ViewRootImpl implements ViewParent,
View.AttachInfo.Callbacks, ThreadedRenderer.DrawCallbacks {
private void performTraversals() {
try {
......
// relayoutWindow 之后 Surface 便被填充了 IGraphicBufferProducer, 可以正常使用了
relayoutResult = relayoutWindow(params, viewVisibility, insetsPending);
if (!hadSurface) {
if (mSurface.isValid()) {
......
if (mAttachInfo.mThreadedRenderer != null) {
try {
// 执行初始化操作
hwInitialized = mAttachInfo.mThreadedRenderer.initialize(
mSurface);
......
} catch (OutOfResourcesException e) {
......
}
}
}
}
}
......
}
}
可以看到 ThreadedRenderer 初始化的时机在 Surface 可用之后进行的, 接下来看看初始化的流程
public final class ThreadedRenderer {
private boolean mInitialized = false;
boolean initialize(Surface surface) throws OutOfResourcesException {
boolean status = !mInitialized;
mInitialized = true;
// 标记为 Enable
updateEnabledState(surface);
nInitialize(mNativeProxy, surface);
return status;
}
private static native void nInitialize(long nativeProxy, Surface window);
}
nInitialize
// frameworks/base/core/jni/android_view_ThreadedRenderer.cpp
static void android_view_ThreadedRenderer_initialize(JNIEnv* env, jobject clazz,
jlong proxyPtr, jobject jsurface) {
RenderProxy* proxy = reinterpret_cast<RenderProxy*>(proxyPtr);
// 调用了 RenderProxy 的 initialize 方法
sp<Surface> surface = android_view_Surface_getSurface(env, jsurface);
proxy->initialize(surface);
}
void RenderProxy::initialize(const sp<Surface>& surface) {
mRenderThread.queue().post(
[ this, surf = surface ]() mutable {
// 调用了 CanvasContext 的 setSurface 函数, 将 surface 保存在 Canvas 的上下文中
mContext->setSurface(std::move(surf));
}
);
}
好的, 可以看到 initialize 方法, 会调用到 CanvasContext.setSurface 函数, 接下来继续探究
void CanvasContext::setSurface(sp<Surface>&& surface) {
ATRACE_CALL();
// 将 surface 保存到 mNativeSurface 成员变量中
mNativeSurface = std::move(surface);
ColorMode colorMode = mWideColorGamut ? ColorMode::WideColorGamut : ColorMode::Srgb;
// 为 OpenGL ES 渲染管线绑定输出 Surface
bool hasSurface = mRenderPipeline->setSurface(mNativeSurface.get(), mSwapBehavior, colorMode);
......
}
这里为 mRenderPipeline 注入了 Surface, 其具体操作如下
bool OpenGLPipeline::setSurface(Surface* surface, SwapBehavior swapBehavior, ColorMode colorMode) {
// 销毁之前的 EGLSurfcae
if (mEglSurface != EGL_NO_SURFACE) {
mEglManager.destroySurface(mEglSurface);
mEglSurface = EGL_NO_SURFACE;
}
// 创建 EGLSurface 作为渲染数据的输出 Buffer
if (surface) {
const bool wideColorGamut = colorMode == ColorMode::WideColorGamut;
mEglSurface = mEglManager.createSurface(surface, wideColorGamut);
}
if (mEglSurface != EGL_NO_SURFACE) {
const bool preserveBuffer = (swapBehavior != SwapBehavior::kSwap_discardBuffer);
mBufferPreserved = mEglManager.setPreserveBuffer(mEglSurface, preserveBuffer);
return true;
}
return false;
}
可以看到这里通过 Surface, 创建了一个 EGLSurface, 我们知道 EGLSurface 表示 OpenGL 渲染后数据的输出 Buffer, 有了缓冲区便可以进行渲染管线的操作了
到这里 ThreadedRenderer 的初始化工作便结束了, 接下来就可以探索 mThreadedRenderer.draw 是如何进行硬件绘制的
三. ThreadedRenderer.draw
public final class ViewRootImpl implements ViewParent,
View.AttachInfo.Callbacks, ThreadedRenderer.DrawCallbacks {
......
private boolean draw(boolean fullRedrawNeeded) {
......
final Rect dirty = mDirty;
if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) {
// 若开启了硬件加速, 则使用 OpenGL 的 ThreadedRenderer 进行绘制
if (mAttachInfo.mThreadedRenderer != null && mAttachInfo.mThreadedRenderer.isEnabled()) {
......
mAttachInfo.mThreadedRenderer.draw(mView, mAttachInfo, this, callback);
} else {
// ......软件绘制
}
}
.......
}
}
硬件渲染开启之后, 在 ViewRootImpl.draw 中就会执行 mAttachInfo.mThreadedRenderer.draw(…) 进行 View 的硬件渲染, 下面我们就看看它的具体实现
public final class ThreadedRenderer {
// Native 层 RootRenderNode 的 Java 包装类
private RenderNode mRootNode;
// Native 层 RenderProxy 句柄
private long mNativeProxy;
void draw(View view, AttachInfo attachInfo, DrawCallbacks callbacks,
FrameDrawingCallback frameDrawingCallback) {
......
// 1. 更新 mRootNode 的 DisplayList
updateRootDisplayList(view, callbacks);
......
// 2. 同步绘制渲染帧
int syncResult = nSyncAndDrawFrame(mNativeProxy, frameInfo, frameInfo.length);
......
}
}
好的, 可以看到 ThreadedRenderer 主要进行了两个操作
- 更新 mRootNode 的 DisplayList
- 调用 nSyncAndDrawFrame 执行渲染操作
接下来我们一一分析
一) 更新 mRootNode 的 DisplayList
public final class ThreadedRenderer {
private void updateRootDisplayList(View view, DrawCallbacks callbacks) {
......
// 视图需要更新 || 当前的根渲染器中的数据已经无效了, 会进入如下分支
if (mRootNodeNeedsUpdate || !mRootNode.isValid()) {
// 1. 构建根结点的 Canvas
DisplayListCanvas canvas = mRootNode.start(mSurfaceWidth, mSurfaceHeight);
try {
......
// 2. 调用 view.updateDisplayListIfDirty() 更新 DecorView 的 DisplayList, 返回 View 的 RenderNode
// 3. 将 DecorView 的 RenderNode 中更新的 DisplayList 数据, 保存到根结点的 Canvas 中
canvas.drawRenderNode(view.updateDisplayListIfDirty());
......
} finally {
// 4. 将根结点 Canvas 中的 DisplayList 注入根结点的 RenderNode
mRootNode.end(canvas);
}
}
}
}
好的, 可以看到渲染的操作主要有三步
- 调用 mRootNode.start 构建根结点的 Canvas 对象
- 调用 DecorView.updateDisplayListIfDirty 更新 View 的 DisplayList
- 调用 DisplayListCanvas.drawRenderNode 将 View 的 DisplayList 注入根结点的 Canvas 中
- 调用 mRootNode.end 将根结点的 Canvas 中记录的 DisplayList 数据保存到 mRootNode 中
上的步骤看起来比较绕, 我们先一一分析, 分析之后再进行总结
1. 构建根结点的 Canvas 对象
public class RenderNode {
public DisplayListCanvas start(int width, int height) {
return DisplayListCanvas.obtain(this, width, height);
}
}
public final class DisplayListCanvas extends RecordingCanvas {
static DisplayListCanvas obtain(@NonNull RenderNode node, int width, int height) {
......
DisplayListCanvas canvas = sPool.acquire();
if (canvas == null) {
canvas = new DisplayListCanvas(node, width, height);
} else {
......
}
canvas.mNode = node;
canvas.mWidth = width;
canvas.mHeight = height;
return canvas;
}
private DisplayListCanvas(@NonNull RenderNode node, int width, int height) {
super(nCreateDisplayListCanvas(node.mNativeRenderNode, width, height));
mDensity = 0;
}
private static native long nCreateDisplayListCanvas(long node, int width, int height);
}
DisplayListCanvas 的创建, 会调用 nCreateDisplayListCanvas 方法, 接下来看看它的 native 实现
// frameworks/base/core/jni/android_view_DisplayListCanvas.cpp
static jlong android_view_DisplayListCanvas_createDisplayListCanvas(jlong renderNodePtr,
jint width, jint height) {
// 获取 RendererNode
RenderNode* renderNode = reinterpret_cast<RenderNode*>(renderNodePtr);
// 调用 create_recording_canvas
return reinterpret_cast<jlong>(Canvas::create_recording_canvas(width, height, renderNode));
}
// frameworks/base/libs/hwui/hwui/Canvas.cpp
Canvas* Canvas::create_recording_canvas(int width, int height, uirenderer::RenderNode* renderNode) {
if (uirenderer::Properties::isSkiaEnabled()) {
// 若是允许使用 skia, 则创建 SkiaRecordingCanvas
return new uirenderer::skiapipeline::SkiaRecordingCanvas(renderNode, width, height);
}
// 反之, 则创建 RecordingCanvas
return new uirenderer::RecordingCanvas(width, height);
}
也就是说 DisplayListCanvas 它会关联一个 SkiaRecordingCanvas/RecordingCanvas
这里主要看看 RecordingCanvas 的实现
// frameworks/base/libs/hwui/RecordingCanvas.cpp
RecordingCanvas::RecordingCanvas(size_t width, size_t height)
: mState(*this), mResourceCache(ResourceCache::getInstance()) {
resetRecording(width, height);
}
void RecordingCanvas::resetRecording(int width, int height, RenderNode* node) {
// 创建了 DisplayList
mDisplayList = new DisplayList();
// 初始化记录的栈
mState.initializeRecordingSaveStack(width, height);
mDeferredBarrierType = DeferredBarrierType::InOrder;
}
// frameworks/base/libs/hwui/DisplayList.cpp
DisplayList::DisplayList()
: projectionReceiveIndex(-1)
, stdAllocator(allocator)
, chunks(stdAllocator)
, ops(stdAllocator)
, children(stdAllocator)
, bitmapResources(stdAllocator)
, pathResources(stdAllocator)
, patchResources(stdAllocator)
, paints(stdAllocator)
, regions(stdAllocator)
, referenceHolders(stdAllocator)
, functors(stdAllocator)
, vectorDrawables(stdAllocator) {}
// frameworks/base/libs/hwui/CanvasState.cpp
void CanvasState::initializeRecordingSaveStack(int viewportWidth, int viewportHeight) {
if (mWidth != viewportWidth || mHeight != viewportHeight) {
mWidth = viewportWidth;
mHeight = viewportHeight;
mFirstSnapshot.initializeViewport(viewportWidth, viewportHeight);
mCanvas.onViewportInitialized();
}
freeAllSnapshots();
mSnapshot = allocSnapshot(&mFirstSnapshot, SaveFlags::MatrixClip);
mSnapshot->setRelativeLightCenter(Vector3());
mSaveCount = 1;
}
RecordingCanvas 这个 Canvas 与软件渲染的 SkiaCanvas 完全不同
- SkiaCanvas 将 SkBitmap 作为缓冲区, 所有的绘制操作会直接写入到缓冲区中
- RecordingCanvas 持有了 DisplayList 和 CanvasState 对象, 这意味着它并没有真正的执行绘制, 而是通过 DisplayList 记录了 View 的绘制动作
了解了硬件渲染的 Canvas 与软件渲染 Canvas 的不同之后, 接下来我们就看看 DecorView 的 updateDisplayListIfDirty 的操作
2. updateDisplayListIfDirty 捕获 View 的绘制动作
public class View {
final RenderNode mRenderNode;
public View(Context context) {
......
// 可见在硬件绘制中, 每一个 View 都持有一个 RenderNode
mRenderNode = RenderNode.create(getClass().getName(), this);
......
}
public RenderNode updateDisplayListIfDirty() {
final RenderNode renderNode = mRenderNode;
.....
if ((mPrivateFlags & PFLAG_DRAWING_CACHE_VALID) == 0
|| !renderNode.isValid() || (mRecreateDisplayList)) {
// 1. 当前 View 中的渲染数据有效
if (renderNode.isValid() && !mRecreateDisplayList) {
// 1.1 将更新 Render 的操作分发给子 View, 该方法会在 ViewGroup 中重写
dispatchGetDisplayList();
// 1.2 返回该 View 的 RenderNode
return renderNode;
}
// 2. 走到这里说明当前 View 的渲染数据已经失效了, 需要重新构建渲染数据
mRecreateDisplayList = true;
int width = mRight - mLeft;
int height = mBottom - mTop;
int layerType = getLayerType();
// 2.1 通过渲染器构建一个 DisplayListCanvas 画笔, 画笔的可作用的区域为 width, height
final DisplayListCanvas canvas = renderNode.start(width, height);
try {
if (layerType == LAYER_TYPE_SOFTWARE) {
......
} else {
......
// 判断是否需要绘制子孩子
if ((mPrivateFlags & PFLAG_SKIP_DRAW) == PFLAG_SKIP_DRAW) {
// 2.2 分发绘制动作
dispatchDraw(canvas);
} else {
// 2.3 仅绘制自身
draw(canvas);
}
}
} finally {
// 3. 表示当前 View 的渲染数据已经保存在 Canvas 中了
// 将它的数据传递到渲染器
renderNode.end(canvas);
}
} else {
......
}
return renderNode;
}
}
从 View 的构造函数中可以看到每一个 View 都持有一个 RenderNode 对象, DecorView.updateDisplayListIfDirty 执行操作如下
- 当前 View 渲染数据依旧是有效的, 并且没有要求重绘
- 调用 dispatchGetDisplayList 更新子 View 的 DisplayList
- 遍历结束之后直接返回 当前现有的渲染器结点对象
- 当前 View 渲染数据无效了
- 构建 Canvas 对象
- 调用 dispatchDraw 分发绘制操作
- 调用 RenderNode.end 将 Canvas 中的 DisplayList 注入到 RenderNode 中
好的, 从这里我们就可以看出硬件绘制的优势了, 通过 RenderNode 可以来判断当前 View 是否需要重绘, 若是不需要则直接调用 dispatchGetDisplayList 更新子 View 的 RenderNode 中的 DisplayList
比起软件渲染只要 invalidate 就会触发整体重绘的实现, 使用 RenderNode 和 DisplayList 的实现无疑要高效的多
这里我们再看看 dispatchGetDisplayList 和 RenderNode.end 的实现
1) dispatchGetDisplayList
public abstract class ViewGroup extends View implements ViewParent, ViewManager {
protected void dispatchGetDisplayList() {
final int count = mChildrenCount;
final View[] children = mChildren;
for (int i = 0; i < count; i++) {
final View child = children[i];
if (((child.mViewFlags & VISIBILITY_MASK) == VISIBLE || child.getAnimation() != null)) {
// 重新构建子 View 的 DisplayList
recreateChildDisplayList(child);
}
}
......
}
private void recreateChildDisplayList(View child) {
child.mRecreateDisplayList = (child.mPrivateFlags & PFLAG_INVALIDATED) != 0;
child.mPrivateFlags &= ~PFLAG_INVALIDATED;
// 调用了子 View 的 updateDisplayListIfDirty
child.updateDisplayListIfDirty();
child.mRecreateDisplayList = false;
}
}
可以看到这里循环的调用了子 View 的 updateDisplayListIfDirty 方法实现, 只更新了需要重绘的 View 的 DisplayList
2) RenderNode.end 结束绘制动作
public class RenderNode {
public void end(DisplayListCanvas canvas) {
// 1. 结束 Canvas 数据的采集
long displayList = canvas.finishRecording();
// 2. 将采集到的 DisplayList 保存到 Native 的结点中
nSetDisplayList(mNativeRenderNode, displayList);
canvas.recycle();
}
}
可以看到 RenderNode.end 中主要有两步操作, 首先调用 DisplayListCanvas.finishRecording 返回内部保存的 DisplayList, 然后将 DisplayList 注入到 Native 层的 RenderNode 中
Step1 返回 DisplayList
public final class DisplayListCanvas extends RecordingCanvas {
long finishRecording() {
return nFinishRecording(mNativeCanvasWrapper);
}
private static native long nFinishRecording(long renderer);
}
// frameworks/base/core/jni/android_view_DisplayListCanvas.cpp
static jlong android_view_DisplayListCanvas_finishRecording(jlong canvasPtr) {
// 调用了 RecordingCanvas 的 finishRecording
Canvas* canvas = reinterpret_cast<Canvas*>(canvasPtr);
return reinterpret_cast<jlong>(canvas->finishRecording());
}
// frameworks/base/libs/hwui/RecordingCanvas.cpp
DisplayList* RecordingCanvas::finishRecording() {
restoreToCount(1);
mPaintMap.clear();
mRegionMap.clear();
mPathMap.clear();
DisplayList* displayList = mDisplayList;
mDisplayList = nullptr;
mSkiaCanvasProxy.reset(nullptr);
return displayList;
}
从这里可以看出, finishRecording 的操作会将绘制过程中的 DisplayList 返回, 接下来看看如何将 DisplayList 返回给 RenderNode
Step2 将 DisplayList 保存到 RenderNode 中
// frameworks/base/core/jni/android_view_RenderNode.cpp
static void android_view_RenderNode_setDisplayList(JNIEnv* env,
jobject clazz, jlong renderNodePtr, jlong displayListPtr) {
RenderNode* renderNode = reinterpret_cast<RenderNode*>(renderNodePtr);
DisplayList* newData = reinterpret_cast<DisplayList*>(displayListPtr);
renderNode->setStagingDisplayList(newData);
}
// frameworks/base/libs/hwui/RenderNode.cpp
void RenderNode::setStagingDisplayList(DisplayList* displayList) {
mValid = (displayList != nullptr);
mNeedsDisplayListSync = true;
delete mStagingDisplayList;
// 将 Canvas 的数据保存到 mStagingDisplayList 中
mStagingDisplayList = displayList;
}
好的, 到这里我们 Canvas 记录的 DisplayList 数据就保存到了 mStagingDisplayList 变量中了
整个 View 更新 DisplayList 的流程如下所示
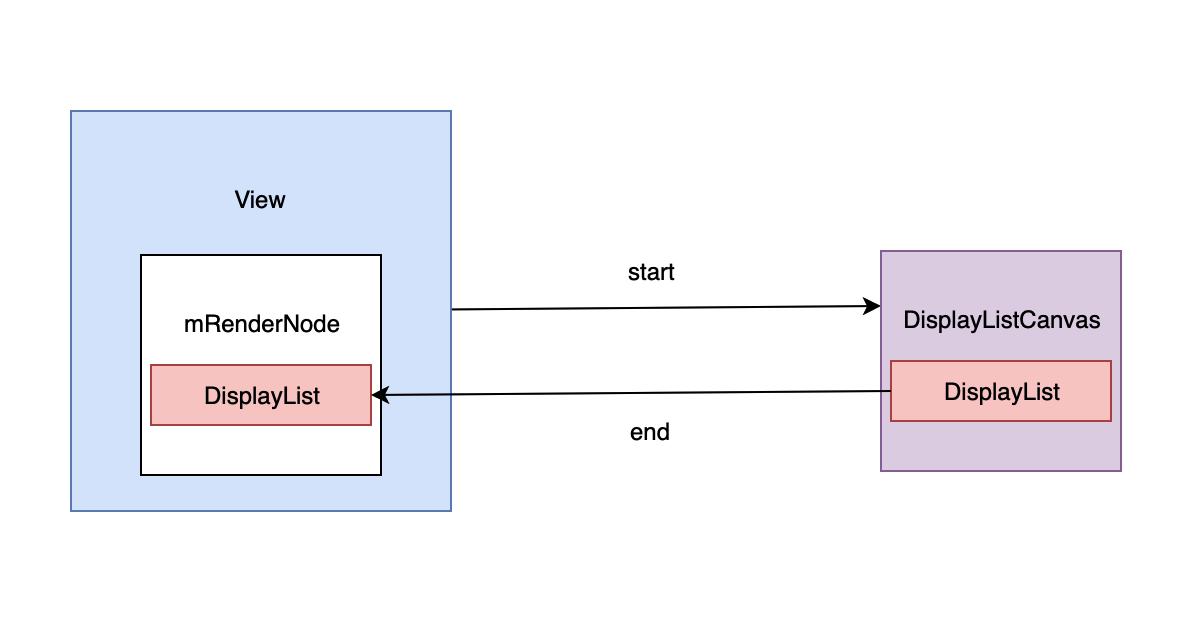
View 的 DisplayList 重构完成之后, 只需要将它的 DisplayList 保存到 ThreadedRenderer 的 mRootNode 中, 整个 DisplayList 的更新动作就完成了
3. 回顾
整个 DisplayList 的更新流程如下所示
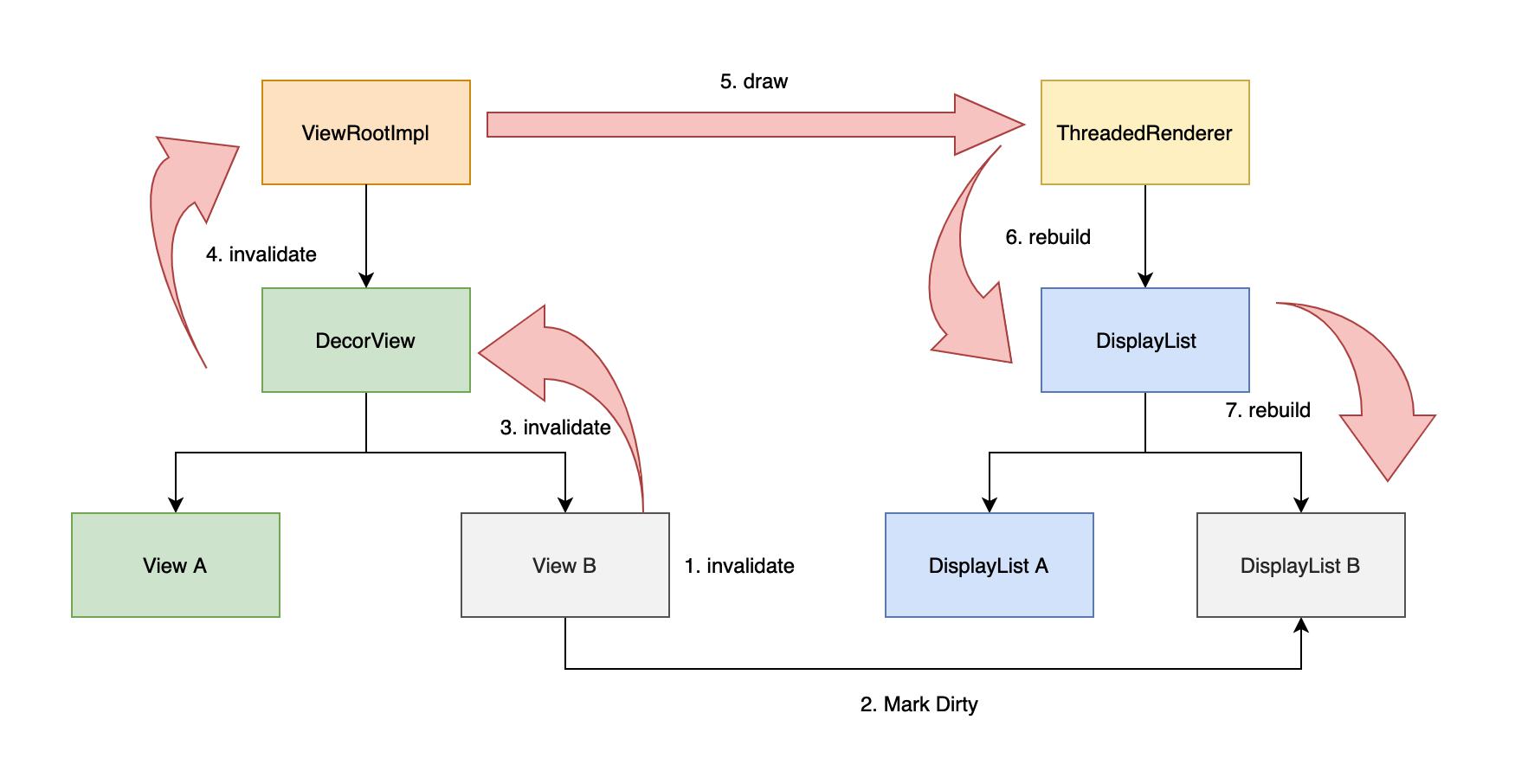
了解了硬件渲染 DisplayList 的重构之后, 接下来我们看看 nSyncAndDrawFrame 是如何在子线程执行渲染操作的
二) nSyncAndDrawFrame 子线程渲染
ThreadedRenderer 通过 nSyncAndDrawFrame 将数据发送给 SurfaceFlinger, 这里看看它的具体操作
// frameworks/base/core/jni/android_view_ThreadedRenderer.cpp
static int android_view_ThreadedRenderer_syncAndDrawFrame(JNIEnv* env, jobject clazz,
jlong proxyPtr, jlongArray frameInfo, jint frameInfoSize) {
.....
// 获取渲染器代理
RenderProxy* proxy = reinterpret_cast<RenderProxy*>(proxyPtr);
env->GetLongArrayRegion(frameInfo, 0, frameInfoSize, proxy->frameInfo());
// 调用 syncAndDrawFrame 函数
return proxy->syncAndDrawFrame();
}
// frameworks/base/libs/hwui/renderthread/RenderProxy.cpp
int RenderProxy::syncAndDrawFrame() {
return mDrawFrameTask.drawFrame();
}
// frameworks/base/libs/hwui/renderthread/DrawFrameTask.cpp
int DrawFrameTask::drawFrame() {
......
mSyncResult = SyncResult::OK;
mSyncQueued = systemTime(CLOCK_MONOTONIC);
postAndWait();
return mSyncResult;
}
void DrawFrameTask::postAndWait() {
AutoMutex _lock(mLock);
// 交由渲染线程去执行这个 run 任务
mRenderThread->queue().post([this]() { run(); });
mSignal.wait(mLock);
}
可以看到, 这里调用了 DrawFrameTask 的 postAndWait 函数, 并且这个绘制任务投放到 RenderThread 的队列中执行, 这里我们看看执行的具体内容
// frameworks/base/libs/hwui/renderthread/DrawFrameTask.cpp
void DrawFrameTask::run() {
......
if (CC_LIKELY(canDrawThisFrame)) {
// 请求 Context 绘制当前帧
context->draw();
} else {
......
}
if (!canUnblockUiThread) {
unblockUiThread();
}
}
void CanvasContext::draw() {
SkRect dirty;
mDamageAccumulator.finish(&dirty);
mCurrentFrameInfo->markIssueDrawCommandsStart();
Frame frame = mRenderPipeline->getFrame();
SkRect windowDirty = computeDirtyRect(frame, &dirty);
// 1. 通知渲染管线绘制数据
bool drew = mRenderPipeline->draw(frame, windowDirty, dirty, mLightGeometry, &mLayerUpdateQueue,
mContentDrawBounds, mOpaque, mWideColorGamut, mLightInfo,
mRenderNodes, &(profiler()));
int64_t frameCompleteNr = mFrameCompleteCallbacks.size() ? getFrameNumber() : -1;
waitOnFences();
bool requireSwap = false;
// 2. 通知渲染管线将数据, 交换到 Surface 的缓冲区中
bool didSwap =
mRenderPipeline->swapBuffers(frame, drew, windowDirty, mCurrentFrameInfo, &requireSwap);
mIsDirty = false;
......
}
可以看到最终的绘制操作是在 CanvasContext 中交由渲染管线去执行的, 这里主要有两个步骤
- 通过 mRenderPipeline->draw, 将 RenderNode 中的 DisplayList 记录的数据绘制到 Surface 的缓冲区
- 通过 mRenderPipeline->swapBuffers 将缓冲区的数据推送到 Surface 的缓冲区中, 等待 SurfaceFlinger 的合成操作
至此, 一次硬件绘制就完成了
总结
可以看到 View 的硬件渲染比起软件渲染要复杂的多, 笔者也有很多内容没有看到, 旨在理清硬件渲染的流程, 这里做个简单的回顾
- ThreadRenderer 的创建
- 会创建一个根结点 RenderNode 用于记录所有的绘制动作 DisplayList
- 创建 RenderProxy 执行渲染操作
- ThreadRenderer 的初始化
- 将 Surface 的缓冲区绑定到 RenderProxy 的渲染管线 RenderPipeline 中
- ThreadRenderer 的绘制
- 更新 mRootNode 中的 DisplayList
- 更新 View 的 mRenderNode 中的 DisplayList
- 将 View 的 DisplayList 注入到 mRootNode 中
- nSyncAndDrawFrame(在 RenderThread 线程执行)
- 通过 mRenderPipeline->draw 执行 mRootNode 中的 DisplayList 的绘制动作
- 通过 mRenderPipeline->swapBuffer 将数据推送到 GraphicBuffer 中
- 更新 mRootNode 中的 DisplayList
硬件绘制与软件绘制差异
1. 从渲染机制
- 硬件绘制使用的是 OpenGL/ Vulkan, 支持 3D 高性能图形绘制
- 软件绘制使用的是 Skia, 仅支持 2D 图形绘制
2. 渲染效率上
- 硬件绘制
- 在 Android 5.0 之后引入了 RendererThread, 它将 OpenGL 图形栅格化的操作全部投递到了这个线程
- 硬件绘制会跳过渲染数据无变更的 View, 直接分发给子视图
- 软件绘制
- 在将数据投入 SurfaceFlinger 之前, 所有的操作均在主线程执行
- 不会跳过无变化的 View
因此硬件绘制较之软件绘制会更加流畅
2. 从内存消耗上
硬件绘制消耗的内存要高于软件绘制, 但在当下大内存手机时代, 用空间去换时间还是非常值得的
3. 从兼容性上
- 硬件绘制的 OpenGL 在各个 Android 版本的支持上会有一些不同, 常有因为兼容性出现的系统 bug
- 软件绘制的 Skia 库从 Android 1.0 便屹立不倒, 因此它的兼容性要好于硬件绘制