前言
在前面的分析中, 我们了解了 SurfaceFlinger 的启动流程, 得知 SurfaceFlinger 对热插拔事件的处理
- onHotplugReceived
- onRefreshReceived
- onVsyncReceived
这里我们主要分析一下对 onVsyncReceived 函数对垂直同步信号 Vsync(屏幕刷新一次之后便会产生一个 Vsync 信号) 的处理
void SurfaceFlinger::onVsyncReceived(int32_t sequenceId,
hwc2_display_t displayId, int64_t timestamp) {
Mutex::Autolock lock(mStateLock);
// Ignore any vsyncs from a previous hardware composer.
if (sequenceId != getBE().mComposerSequenceId) {
return;
}
// 通知底层, 接收到了垂直同步信号
int32_t type;
if (!getBE().mHwc->onVsync(displayId, timestamp, &type)) {
return;
}
bool needsHwVsync = false;
{
Mutex::Autolock _l(mHWVsyncLock);
if (type == DisplayDevice::DISPLAY_PRIMARY && mPrimaryHWVsyncEnabled) {
// 将这个垂直同步的信号添加到 mPrimaryDispSync 中, 处理 HW-VSYNC 的转换操作
needsHwVsync = mPrimaryDispSync.addResyncSample(timestamp);
}
}
.......
}
可以看到 SurfaceFlinger 收到垂直同步信号之后的操作如下
- 通知 HwComposer 收到了垂直同步信号
- 调用 mPrimaryDispSync.addResyncSample 处理 HW-VSYNC 到 SW-VSYNC 的转化
关于 mPrimaryDispSync 的创建, 我们在 SurfaceFlinger 启动的构造函数中已经分析了, 其内部持有一个 DispSyncThread 线程, 在 threadLoop 中持续的等待 Vsync 信号的到来并执行分发
关于 HAL 层的操作, 我们就不关心了, 这里主要看看后面的操作
一. VSYNC 的分发
一) DispSync 转换 HW-VSYNC
// frameworks/native/services/surfaceflinger/DispSync.cpp
bool DispSync::addResyncSample(nsecs_t timestamp) {
Mutex::Autolock lock(mMutex);
size_t idx = (mFirstResyncSample + mNumResyncSamples) % MAX_RESYNC_SAMPLES;
mResyncSamples[idx] = timestamp;
if (mNumResyncSamples == 0) {
mPhase = 0;
mReferenceTime = timestamp;
ALOGV("[%s] First resync sample: mPeriod = %" PRId64 ", mPhase = 0, "
"mReferenceTime = %" PRId64,
mName, ns2us(mPeriod), ns2us(mReferenceTime));
mThread->updateModel(mPeriod, mPhase, mReferenceTime);
}
if (mNumResyncSamples < MAX_RESYNC_SAMPLES) {
mNumResyncSamples++;
} else {
mFirstResyncSample = (mFirstResyncSample + 1) % MAX_RESYNC_SAMPLES;
}
// 调用了 updateModelLocked 函数
updateModelLocked();
......
return !modelLocked;
}
可以看到 mPrimaryDispSync.addResyncSample 函数, 调用了 updateModelLocked 函数, 从字面意思上来看, 这个很有可能是解除 threadLoop 中管程 wait 的关键
void DispSync::updateModelLocked() {
......
if (mNumResyncSamples >= MIN_RESYNC_SAMPLES_FOR_UPDATE) {
nsecs_t durationSum = 0;
nsecs_t minDuration = INT64_MAX;
nsecs_t maxDuration = 0;
for (size_t i = 1; i < mNumResyncSamples; i++) {
size_t idx = (mFirstResyncSample + i) % MAX_RESYNC_SAMPLES;
size_t prev = (idx + MAX_RESYNC_SAMPLES - 1) % MAX_RESYNC_SAMPLES;
nsecs_t duration = mResyncSamples[idx] - mResyncSamples[prev];
durationSum += duration;
minDuration = min(minDuration, duration);
maxDuration = max(maxDuration, duration);
}
// Exclude the min and max from the average
durationSum -= minDuration + maxDuration;
mPeriod = durationSum / (mNumResyncSamples - 3);
......
// Artificially inflate the period if requested.
mPeriod += mPeriod * mRefreshSkipCount;
// 调用 DispSyncThread 的 updateModel
mThread->updateModel(mPeriod, mPhase, mReferenceTime);
mModelUpdated = true;
}
}
DispSync::updateModelLocked 中主要是一些周期的更新操作, 我们主要是为了理清 Vsync 的走向, 关于 HW-VSYNC 到 SW-VSYNC 的转化, 可以查阅这篇文章
我们直接看看 DispSyncThread 的 updateModel 操作
class DispSyncThread : public Thread {
public:
void updateModel(nsecs_t period, nsecs_t phase, nsecs_t referenceTime) {
......
mPeriod = period;
mPhase = phase;
mReferenceTime = referenceTime;
// 唤醒阻塞的 threadLoop
mCond.signal();
}
}
到这里便可以看到它唤醒了阻塞 DispSyncThread 中阻塞的 threadLoop, 既然如此一来 threadLoop 就可以执行垂直同步的分发了
接下来看看 threadLoop 如何分发这个 SW-VSYNC 事件
二) 分发 SW-VSYNC
// frameworks/native/services/surfaceflinger/DispSync.cpp
virtual bool threadLoop() {
status_t err;
nsecs_t now = systemTime(SYSTEM_TIME_MONOTONIC);
while (true) {
Vector<CallbackInvocation> callbackInvocations;
nsecs_t targetTime = 0;
{ // Scope for lock
// 1. 若 mPeriod 为 0, 则循环等待
if (mPeriod == 0) {
err = mCond.wait(mMutex);
if (err != NO_ERROR) {
ALOGE("error waiting for new events: %s (%d)", strerror(-err), err);
return false;
}
continue;
}
......
// 2. 收集 SW-VSYNC 处理者
callbackInvocations = gatherCallbackInvocationsLocked(now);
}
if (callbackInvocations.size() > 0) {
// 3. 分发 SW-VSYNC 事件
fireCallbackInvocations(callbackInvocations);
}
}
return false;
}
我们知道, 通过 DispSyncThread.updateModel 的函数调用, threadLoop 的阻塞便解除了, 进而就可以执行后续的操作了
我们先看看收集回调方法的实现
1. 收集信号响应者
// frameworks/native/services/surfaceflinger/DispSync.cpp
Vector<CallbackInvocation> gatherCallbackInvocationsLocked(nsecs_t now) {
if (kTraceDetailedInfo) ATRACE_CALL();
.......
Vector<CallbackInvocation> callbackInvocations;
nsecs_t onePeriodAgo = now - mPeriod;
for (size_t i = 0; i < mEventListeners.size(); i++) {
nsecs_t t = computeListenerNextEventTimeLocked(mEventListeners[i], onePeriodAgo);
if (t < now) {
// 将 mEventListeners 中的 Callback 封装进 CallbackInvocation
CallbackInvocation ci;
ci.mCallback = mEventListeners[i].mCallback;
ci.mEventTime = t;
.......
callbackInvocations.push(ci);
mEventListeners.editItemAt(i).mLastEventTime = t;
}
}
return callbackInvocations;
}
收集回调的方式也比较简单, 它将 mEventListeners 中的 mCallback 封装进了 CallbackInvocation 中
这里我们有个疑问, 这个 EnventListener 中的 Callback 是什么时候注入的呢?
我们在分析 SurfaceFlinger 的启动时, 有分析过 EventThread 的 waitForEventLocked 函数, 这里回顾一下
// frameworks/native/services/surfaceflinger/EventThread.cpp
Vector<sp<EventThread::Connection> > EventThread::waitForEventLocked(
std::unique_lock<std::mutex>* lock, DisplayEventReceiver::Event* event) {
Vector<sp<EventThread::Connection> > signalConnections;
while (signalConnections.isEmpty() && mKeepRunning) {
bool eventPending = false;
bool waitForVSync = false;
size_t vsyncCount = 0;
nsecs_t timestamp = 0;
......
// Here we figure out if we need to enable or disable vsyncs
if (timestamp && !waitForVSync) {
// 没有 Connection, 则调用 enableVSyncLocked
disableVSyncLocked();
} else if (!timestamp && waitForVSync) {
// 至少有一个连接在等待 Vsync 信号, 因此调用 enableVSyncLocked 函数
enableVSyncLocked();
}
......
}
return signalConnections;
}
当 EventThread 存在 Connection 在等待 Vsync 信号时, 则会调用 enableVSyncLocked 函数
// frameworks/native/services/surfaceflinger/EventThread.cpp
void EventThread::enableVSyncLocked() {
if (!mUseSoftwareVSync) {
// never enable h/w VSYNC when screen is off
if (!mVsyncEnabled) {
mVsyncEnabled = true;
// 调用了 DispSyncSource 的 Callback
mVSyncSource->setCallback(this);
// 调用了 DispSyncSource 的 setVSyncEnabled
mVSyncSource->setVSyncEnabled(true);
}
}
mDebugVsyncEnabled = true;
}
可以看到 EventThread 中调用了 DispSyncSource 的 setCallback 和 setVSyncEnabled, 他们的函数实现如下
// frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
class DispSyncSource final : public VSyncSource, private DispSync::Callback {
void setCallback(VSyncSource::Callback* callback) override{
Mutex::Autolock lock(mCallbackMutex);
// 保存 EventThread 传递过来的 Callback
mCallback = callback;
}
void setVSyncEnabled(bool enable) override {
Mutex::Autolock lock(mVsyncMutex);
if (enable) {
// 调用了 DispSync.addEventListener 来添加一个 EventListener, 将其自身作为 Callback 传入
status_t err = mDispSync->addEventListener(mName, mPhaseOffset,
static_cast<DispSync::Callback*>(this));
.......
} else {
// 移除事件回调
status_t err = mDispSync->removeEventListener(
static_cast<DispSync::Callback*>(this));
......
}
mEnabled = enable;
}
}
到这里我们就知晓了, 其实 DispSync 中 mEventListerer 的回调 mCallback 其实就是 DispSyncSource, DispSyncSource 中会持有 EventThread 对象的引用 mCallback
下面我们看看 fireCallbackInvocations
2. 分发给响应者
void fireCallbackInvocations(const Vector<CallbackInvocation>& callbacks) {
if (kTraceDetailedInfo) ATRACE_CALL();
for (size_t i = 0; i < callbacks.size(); i++) {
// 调用了 mCallback 的 onDispSyncEvent 来消费这一个 Vsync 信号事件
callbacks[i].mCallback->onDispSyncEvent(callbacks[i].mEventTime);
}
}
遍历 DispSyncSource 集合, 调用 onDispSyncEvent 分发这个 Vsync 实现
// frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
class DispSyncSource final : public VSyncSource, private DispSync::Callback {
private:
virtual void onDispSyncEvent(nsecs_t when) {
VSyncSource::Callback* callback;
{
Mutex::Autolock lock(mCallbackMutex);
callback = mCallback;
......
}
// 调用了 mCallback 的 onVSyncEvent
if (callback != nullptr) {
callback->onVSyncEvent(when);
}
}
}
非常简单, DispSyncSource 就是一个代理对象, 它将 DispSyncThread 的 SW-VSYNC 发送到了 EventThread 线程中的 onVSyncEvent 去处理
接下来我们看看 EventThread 对 VSYNC 的处理
三) EventThread 分发 VSYNC
// frameworks/native/services/surfaceflinger/EventThread.cpp
void EventThread::onVSyncEvent(nsecs_t timestamp) {
std::lock_guard<std::mutex> lock(mMutex);
mVSyncEvent[0].header.type = DisplayEventReceiver::DISPLAY_EVENT_VSYNC;
mVSyncEvent[0].header.id = 0;
mVSyncEvent[0].header.timestamp = timestamp;
mVSyncEvent[0].vsync.count++;
// 好的, 这里调用了 notify_all, 解除了 EventThread 中 waitForEventLocked 的阻塞
mCondition.notify_all();
}
在 SurfaceFlinger 启动的过程中, 我们知道 EventThread 的 threadMain 在解除了阻塞之后, 会调用将这个事件写入 EvnetThread 的 Connection 的 BitTube 中
我们知道 SurfaceFlinger 一共有两个 EventThread
- EventThread-app: 唤醒应用进程执行绘制操作
- EventThread-sf: 唤醒 SurfaceFlinger 的主线程, 执行图层合成
这里我们主要关心 SurfaceFlinger 对 VSYNC 的处理, 关于应用进程与 Choreographer 的连接以后有机会再分析
SurfaceFlinger 处理 Vsync 信号
接下来我们看看 onMessageReceived 的函数到底是如何处理这个垂直同步信号的
void SurfaceFlinger::onMessageReceived(int32_t what) {
ATRACE_CALL();
switch (what) {
case MessageQueue::INVALIDATE: {
......
bool refreshNeeded = handleMessageTransaction();
// 1. 调用了 handleMessageInvalidate
refreshNeeded |= handleMessageInvalidate();
refreshNeeded |= mRepaintEverything;
if (refreshNeeded) {
// 2. 调用了 signalRefresh 函数
signalRefresh();
}
break;
}
......
}
}
void SurfaceFlinger::signalRefresh() {
mRefreshPending = true;
mEventQueue->refresh();
}
// frameworks/native/services/surfaceflinger/MessageQueue.cpp
void MessageQueue::refresh() {
mHandler->dispatchRefresh();
}
void MessageQueue::Handler::dispatchRefresh() {
if ((android_atomic_or(eventMaskRefresh, &mEventMask) & eventMaskRefresh) == 0) {
// 2.1 发送 MessageQueue::REFRESH 类型的 Message
mQueue.mLooper->sendMessage(this, Message(MessageQueue::REFRESH));
}
}
好的可以看到 INVALIDATE 消息, 首先会调用 handleMessageInvalidate, 判断是否需要重新刷新界面, 若需要则会调用 signalRefresh 进行数据重绘
三) 回顾
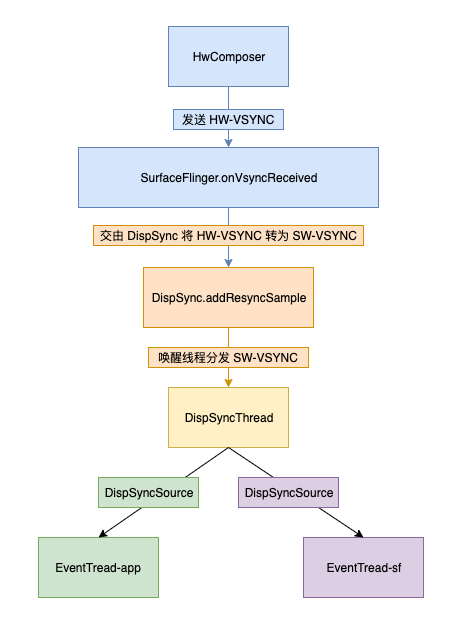
Vsync 的信号分发流程如下
- DispSync 处理 HW-VSYNC
- DispSyncThread 分发 SW-VSYNC
- 找寻响应者 DispSyncSource 集合
- 调用 DispSyncSource 分发 SW-VSYNC 到 EventThread
- EventThread 将 SW-VSYNC 写入 Connection 的 BitTube
- EventThread-app
- 唤醒应用进程的 Choreographer 执行帧的准备
- EventThread-sf: 唤醒 SurfaceFlinger 的主线程
- 处理 INVALIDATE 消息
- 处理 REFRESH 消息
- EventThread-app
好的, 接下来我们看看 SurfaceFlinger 是如何处理 INVALIDATE 消息的
二. 处理 INVALIDATE 消息
bool SurfaceFlinger::handleMessageInvalidate() {
return handlePageFlip();
}
bool SurfaceFlinger::handlePageFlip()
{
bool visibleRegions = false;
bool frameQueued = false;
bool newDataLatched = false;
......
// 遍历所有的 Layer, 若需要展示, 则将他们添加到 mLayersWithQueuedFrames 中, 表示待重绘
mDrawingState.traverseInZOrder([&](Layer* layer) {
if (layer->hasQueuedFrame()) {
frameQueued = true;
if (layer->shouldPresentNow(mPrimaryDispSync)) {
mLayersWithQueuedFrames.push_back(layer);
} else {
layer->useEmptyDamage();
}
} else {
layer->useEmptyDamage();
}
});
// 遍历 mLayersWithQueuedFrames 中的 Layer
for (auto& layer : mLayersWithQueuedFrames) {
// 调用 Layer 的 latchBuffer 函数, 去队列中获取一个缓冲区
const Region dirty(layer->latchBuffer(visibleRegions, latchTime));
layer->useSurfaceDamage();
invalidateLayerStack(layer, dirty);
// 若是成功锁定了一个缓冲, 则说明 GraphicBuffer 中, 存在该 Layer 的新渲染数据
if (layer->isBufferLatched()) {
newDataLatched = true;
}
}
......
// Only continue with the refresh if there is actually new work to do
return !mLayersWithQueuedFrames.empty() && newDataLatched;
}
从这里我们可以看到, 当 invalidate 消息到来时会执行如下的操作
- 按照 Z 轴遍历这个屏幕的所有 Layer, 添加到待合成的队列中
- 遍历待合成队列
- 调用 Layer.latchBuffer 函数, 从 Layer 的队列中获取一个新的缓冲区
- 若缓冲队列中存在, 则说明需要进行重绘
这里我们看看 Layer 是如何锁定缓冲区的
一) Layer.latchBuffer
我们主要关心 Layer 的实现类 BufferLayer
// frameworks/native/services/surfaceflinger/BufferLayer.cpp
Region BufferLayer::latchBuffer(bool& recomputeVisibleRegions, nsecs_t latchTime) {
.....
// 调用 mConsumer 的 updateTexImage 方法更新 Layer 数据
status_t updateResult =
mConsumer->updateTexImage(&r, mFlinger->mPrimaryDispSync,
&mAutoRefresh, &queuedBuffer,
mLastFrameNumberReceived);
......
}
我们在应用进程 Surface 创建的过程中知道, 一个 Surface 会对应 SurfaceFlinger 中的 BufferLayer, 这个 BufferLayer 是支持智能指针的, mConsumer 就是在 onFirstRef 中初始化的, 其实现类为 BufferLayerConsumer
其 updateTexImage 的实现如下
// frameworks/native/services/surfaceflinger/BufferLayerConsumer.cpp
status_t BufferLayerConsumer::updateTexImage(BufferRejecter* rejecter, const DispSync& dispSync,
bool* autoRefresh, bool* queuedBuffer,
uint64_t maxFrameNumber) {
......
// 调用了 acquireBufferLocked 获取一个新的图像缓冲
BufferItem item;
status_t err = acquireBufferLocked(&item, computeExpectedPresent(dispSync), maxFrameNumber);
......
if (queuedBuffer) {
*queuedBuffer = item.mQueuedBuffer;
}
......
return err;
}
updateTexImage 的操作比较复杂, 这里省略了大量的代码, 主要关注一下 acquireBufferLocked 获取缓冲区的操作
status_t BufferLayerConsumer::acquireBufferLocked(BufferItem* item, nsecs_t presentWhen,
uint64_t maxFrameNumber) {
// 1. 通过 ConsumerBase 的 acquireBufferLocked 获取一个新的 Buffer
status_t err = ConsumerBase::acquireBufferLocked(item, presentWhen, maxFrameNumber);
if (err != NO_ERROR) {
return err;
}
// 2. 若取到了新的 GrapicBuffer, 则创建一个新的 Image 缓存起来
if (item->mGraphicBuffer != nullptr) {
mImages[item->mSlot] = new Image(item->mGraphicBuffer, mRE);
}
return NO_ERROR;
}
这里会调用 ConsumerBase 的 acquireBufferLocked
// frameworks/native/libs/gui/ConsumerBase.cpp
status_t ConsumerBase::acquireBufferLocked(BufferItem *item,
nsecs_t presentWhen, uint64_t maxFrameNumber) {
......
// 1. 调用了 mConsumer 的 acquireBuffer 获取一个 BufferItem 对象
status_t err = mConsumer->acquireBuffer(item, presentWhen, maxFrameNumber);
if (err != NO_ERROR) {
return err;
}
// 2. 更新 GraphicBuffer 到 mSlots 中
if (item->mGraphicBuffer != NULL) {
// 清除 mSlots 在 item.mSlot 槽位处的 GraphicBuffer
if (mSlots[item->mSlot].mGraphicBuffer != NULL) {
freeBufferLocked(item->mSlot);
}
mSlots[item->mSlot].mGraphicBuffer = item->mGraphicBuffer;
}
mSlots[item->mSlot].mFrameNumber = item->mFrameNumber;
mSlots[item->mSlot].mFence = item->mFence;
......
return OK;
}
可以看到, 这里调用了 mConsumer 的 acquireBuffer 获取到了 BufferItem 对象, 它就是用来描述一个新的待渲染数据
二) 回顾
INVALIDATE 会触发所有 Layer 的 latch 函数, 尝试去从自己的 Buffer 队列中锁定一块新的 GraphicBuffer
有了新的 GraphicBuffer 之后, 下面需要做的便是 REFRESH 触发 Layer 进行合成了
三. 处理 REFRESH 消息
好的, 可以看到这发送了一条 MessageQueue::REFRESH 消息, 下面我们看看 onMessageReceived 对 MessageQueue::REFRESH 的处理
void SurfaceFlinger::onMessageReceived(int32_t what) {
switch (what) {
......
case MessageQueue::REFRESH: {
handleMessageRefresh();
break;
}
}
}
void SurfaceFlinger::handleMessageRefresh() {
......
// 1. 将 Layer 按照 Z 轴排序
rebuildLayerStacks();
......
// 2. 执行 Layer 的合成并且展示到屏幕
doComposition();
......
}
好的, 可以看到 SurfaceFlinger 的 handleMessageRefresh 中我们需要关心的操作主要有如上所示
- rebuildLayerStacks 负责 Layzer 的排序
- doComposition 负责合并 Layer, 并且输出到屏幕
下面我们逐一查看
一) 将 Layer 按照 Z 轴排序
// frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
void SurfaceFlinger::rebuildLayerStacks() {
......
// rebuild the visible layer list per screen
if (CC_UNLIKELY(mVisibleRegionsDirty)) {
......
// 遍历每一个显示设备
for (size_t dpy=0 ; dpy<mDisplays.size() ; dpy++) {
Region opaqueRegion;
Region dirtyRegion;
// 用来存储按照 Z 轴排序好的 Layer
Vector<sp<Layer>> layersSortedByZ;
Vector<sp<Layer>> layersNeedingFences;
// 获取显示设备描述
const sp<DisplayDevice>& displayDevice(mDisplays[dpy]);
const Transform& tr(displayDevice->getTransform());
const Rect bounds(displayDevice->getBounds());
if (displayDevice->isDisplayOn()) {
// 计算可视的区域
computeVisibleRegions(displayDevice, dirtyRegion, opaqueRegion);
// 遍历每一个 Layers
mDrawingState.traverseInZOrder([&](Layer* layer) {
bool hwcLayerDestroyed = false;
// 若这个 Layer 属于该显示设备
if (layer->belongsToDisplay(displayDevice->getLayerStack(),
displayDevice->isPrimary())) {
// 获取 Layer 绘制的区域
Region drawRegion(tr.transform(
layer->visibleNonTransparentRegion));
drawRegion.andSelf(bounds);
if (!drawRegion.isEmpty()) {
// 添加到集合汇总
layersSortedByZ.add(layer);
} else {
// 清除 HWC 层的 Layer, 让其不可见
hwcLayerDestroyed = layer->destroyHwcLayer(
displayDevice->getHwcDisplayId());
}
} else {
// 清除 HWC 层的 Layer, 让其不可见
hwcLayerDestroyed = layer->destroyHwcLayer(
displayDevice->getHwcDisplayId());
}
// 若这个 Layer 因为 Fence 操作没有被 GPU 释放, 则添加到 layersNeedingFences 集合中
if (hwcLayerDestroyed) {
auto found = std::find(mLayersWithQueuedFrames.cbegin(),
mLayersWithQueuedFrames.cend(), layer);
if (found != mLayersWithQueuedFrames.cend()) {
layersNeedingFences.add(layer);
}
}
});
}
// 为显示设备注入, 按照 Z 轴排序好的 Layers
displayDevice->setVisibleLayersSortedByZ(layersSortedByZ);
// 为显示设备注入, 需要 Fences 等的 GPU 释放缓冲的 Layers
displayDevice->setLayersNeedingFences(layersNeedingFences);
......
}
}
}
可以看到 rebuildLayerStacks 的主要职责是将每个显示设备的 Layer 按照 Z 轴进行排序, 保存到其显示器上下文 DisplayDevice 中
到这里一个显示屏的 Layer 便按照 Z 轴排序好了, 下面我们看看最重要的数据和合成
二) 合成 Layer 展示到屏幕
void SurfaceFlinger::doComposition() {
......
// 遍历每个显示屏
for (size_t dpy=0 ; dpy<mDisplays.size() ; dpy++) {
const sp<DisplayDevice>& hw(mDisplays[dpy]);
if (hw->isDisplayOn()) {
const Region dirtyRegion(hw->getDirtyRegion(repaintEverything));
// 合成 Layer 输出到屏幕
doDisplayComposition(hw, dirtyRegion);
hw->dirtyRegion.clear();
hw->flip();
}
}
}
好的 SurfaceFlinger::doComposition 函数中是真正的负责每个显示屏 Layer 合成的操作, 下面我们就分析一下 doDisplayComposition 函数中做了什么
// frameworks/native/services/surfaceflinger/SurfaceFlinger.cpp
void SurfaceFlinger::doDisplayComposition(
const sp<const DisplayDevice>& displayDevice,
const Region& inDirtyRegion)
{
......
// 1. 调用 doComposeSurfaces
if (!doComposeSurfaces(displayDevice)) return;
// 2. 置换缓冲
displayDevice->swapBuffers(getHwComposer());
}
好的从 doDisplayComposition 函数中主要有两个步骤
- 调用 doComposeSurfaces 合成所有的 Layer
- 调用 swapBuffers 将合成后的数据展示到屏幕
接下来我们一一查看
1. 合成 Layer
bool SurfaceFlinger::doComposeSurfaces(const sp<const DisplayDevice>& displayDevice)
{
const Region bounds(displayDevice->bounds());
const DisplayRenderArea renderArea(displayDevice);
const auto hwcId = displayDevice->getHwcDisplayId();
const bool hasClientComposition = getBE().mHwc->hasClientComposition(hwcId);
.......
if (hasClientComposition) {
......
// 1.1 将当前屏幕的 RE::Surface 中的 EGLContext 置为当前线程的上下文
if (!displayDevice->makeCurrent()) {
.......
return false;
}
......
}
const Transform& displayTransform = displayDevice->getTransform();
// 变量 Display 的 Layer 执行绘制操作
for (auto& layer : displayDevice->getVisibleLayersSortedByZ()) {
const Region clip(bounds.intersect(
displayTransform.transform(layer->visibleRegion)));
if (!clip.isEmpty()) {
switch (layer->getCompositionType(hwcId)) {
......
case HWC2::Composition::Client: {
......
// 1.2 执行每一个 Layer 的 draw 操作
layer->draw(renderArea, clip);
break;
}
default:
break;
}
}
......
}
......
return true;
}
可以看到 Layer 合成的步骤如下
- 将当前屏幕的 RE::Surface 中的 EGLContext 置为当前线程的 GL 上下文
- 遍历屏幕的 Layer, 绘制 Layer 纹理
1) 切换 GL 上下文
// frameworks/native/services/surfaceflinger/DisplayDevice.cpp
bool DisplayDevice::makeCurrent() const {
bool success = mFlinger->getRenderEngine().setCurrentSurface(*mSurface);
......
return success;
}
// frameworks/native/services/surfaceflinger/RenderEngine/RenderEngine.cpp
bool RenderEngine::setCurrentSurface(const android::RE::Surface& surface) {
......
return setCurrentSurface(static_cast<const android::RE::impl::Surface&>(surface));
}
bool RenderEngine::setCurrentSurface(const android::RE::impl::Surface& surface) {
bool success = true;
EGLSurface eglSurface = surface.getEGLSurface();
if (eglSurface != eglGetCurrentSurface(EGL_DRAW)) {
// 更新上下文
success = eglMakeCurrent(mEGLDisplay, eglSurface, eglSurface, mEGLContext) == EGL_TRUE;
if (success && surface.getAsync()) {
eglSwapInterval(mEGLDisplay, 0);
}
}
return success;
}
可以看到这里调用了 eglMakeCurrent, 将 DisplayDevice 中的 RE::Surface 中的 EGLContext 置为当前线程的上下文 , 也就是说接下来 Layer.draw 所有的操作, 均会绘制到 RE::Surface 的 EGLSurface 上
2) 绘制 Layer 纹理
// frameworks/native/services/surfaceflinger/Layer.cpp
void Layer::draw(const RenderArea& renderArea, const Region& clip) const {
onDraw(renderArea, clip, false);
}
这里的 onDraw 会调用其子类的实现, 这里我们看看 BufferLayer 的操作
// frameworks/native/services/surfaceflinger/BufferLayer.cpp
void BufferLayer::onDraw(const RenderArea& renderArea, const Region& clip,
bool useIdentityTransform) const {
......
// 1. 绑定当前 Layer GraphicBuffer 到 OpenGL 的纹理上
status_t err = mConsumer->bindTextureImage();
......
// 2. 使用 OpenGL 进行绘制
drawWithOpenGL(renderArea, useIdentityTransform);
// 3. 解绑纹理
engine.disableTexturing();
}
好的, 从这里可以看到 Layer 的 draw 操作起始就是 OpenGL 的渲染管线的相关操作
我们先看看 mConsumer->bindTextureImage 操作
// frameworks/native/services/surfaceflinger/BufferLayerConsumer.cpp
status_t BufferLayerConsumer::bindTextureImageLocked() {
......
// 调用了 mRE 的 bindExternalTextureImage 操作
mRE.bindExternalTextureImage(mTexName, mCurrentTextureImage->image());
// Wait for the new buffer to be ready.
return doFenceWaitLocked();
}
绑定了纹理之后, 还需要注入纹理的顶点坐标, 其相关操作如下
// frameworks/native/services/surfaceflinger/BufferLayer.cpp
void BufferLayer::drawWithOpenGL(const RenderArea& renderArea, bool useIdentityTransform) const {
const State& s(getDrawingState());
......
float left = float(win.left) / float(s.active.w);
float top = float(win.top) / float(s.active.h);
float right = float(win.right) / float(s.active.w);
float bottom = float(win.bottom) / float(s.active.h);
// 填充 mMesh 的纹理坐标
Mesh::VertexArray<vec2> texCoords(getBE().mMesh.getTexCoordArray<vec2>());
texCoords[0] = vec2(left, 1.0f - top);
texCoords[1] = vec2(left, 1.0f - bottom);
texCoords[2] = vec2(right, 1.0f - bottom);
texCoords[3] = vec2(right, 1.0f - top);
// 获取渲染引擎
auto& engine(mFlinger->getRenderEngine());
engine.setupLayerBlending(mPremultipliedAlpha, isOpaque(s), false /* disableTexture */,
getColor());
// 绘制这个 mMesh
engine.drawMesh(getBE().mMesh);
// 解绑
engine.disableBlending();
......
}
好的, 到这里关于一个 Layer 的 EGL 渲染代码就完成了, 可以看到每一个 Layer 最都会转化为 GL 纹理
等待所有的 Layer 都绘制完成之后, 接下来只需要调用 swapBuffers 就可以将 EGLSurface 中的数据推入屏幕的缓冲队列了
2. 将合成的数据推入屏幕队列
// frameworks/native/services/surfaceflinger/DisplayDevice.cpp
void DisplayDevice::swapBuffers(HWComposer& hwc) const {
if (hwc.hasClientComposition(mHwcDisplayId) || hwc.hasFlipClientTargetRequest(mHwcDisplayId)) {
// 1. 调用了 RE::Surface 的 swapBuffers
mSurface->swapBuffers();
}
// 2. 调用了 FramebufferSurface 的 advanceFrame
status_t result = mDisplaySurface->advanceFrame();
......
}
可以看到 DisplayDevice 的 swapBuffers 的主要操作如下
- 调用 RE::Surface 的 swapBuffers, 将 EGLSurface 中的数据通过 IGraphicBufferProducer 推入屏幕渲染队列
- 调用了 FramebufferSurface 的 advanceFrame, 将缓冲推给硬件进行展示
1) 将数据推入屏幕队列
// frameworks/native/services/surfaceflinger/RenderEngine/Surface.cpp
void Surface::swapBuffers() const {
// 将 mEGLSurface 中绑定的 GraphicBuffer 推入屏幕队列
if (!eglSwapBuffers(mEGLDisplay, mEGLSurface)) {
......
}
}
关于 swapBuffers 的操作, 这里就不再赘述了, 可以查看 EGL 的专栏
下面看看屏幕生产者 FramebufferSurface 是如何从队列中取数据并推给硬件的
2) 生产者将数据推给硬件展示
// frameworks/native/services/surfaceflinger/DisplayHardware/FramebufferSurface.cpp
status_t FramebufferSurface::advanceFrame() {
uint32_t slot = 0;
sp<GraphicBuffer> buf;
sp<Fence> acquireFence(Fence::NO_FENCE);
Dataspace dataspace = Dataspace::UNKNOWN;
// 获取一个屏幕的缓冲
status_t result = nextBuffer(slot, buf, acquireFence, dataspace);
mDataSpace = dataspace;
......
return result;
}
status_t FramebufferSurface::nextBuffer(uint32_t& outSlot,
sp<GraphicBuffer>& outBuffer, sp<Fence>& outFence,
Dataspace& outDataspace) {
Mutex::Autolock lock(mMutex);
BufferItem item;
// 1. 获取一个 GraphicBuffer, 这个 GraphicBuffer 便是 RE::Surface 中 eglSwapBuffers 推入的
status_t err = acquireBufferLocked(&item, 0);
if (err == BufferQueue::NO_BUFFER_AVAILABLE) {
// 1.2 若队列中没有数据, 则将当前帧推入 HAL 层缓冲区
mHwcBufferCache.getHwcBuffer(mCurrentBufferSlot, mCurrentBuffer,
&outSlot, &outBuffer);
return NO_ERROR;
} else if (err != NO_ERROR) {
......
}
......
// 2. 将当前的帧, 置为上一帧
if (mCurrentBufferSlot != BufferQueue::INVALID_BUFFER_SLOT &&
item.mSlot != mCurrentBufferSlot) {
mHasPendingRelease = true;
mPreviousBufferSlot = mCurrentBufferSlot;
mPreviousBuffer = mCurrentBuffer;
}
// 3. 将新获取的 GraphicBuffer 置为当前帧
mCurrentBufferSlot = item.mSlot;
mCurrentBuffer = mSlots[mCurrentBufferSlot].mGraphicBuffer;
mCurrentFence = item.mFence;
outFence = item.mFence;
// 4. 将当前帧推入 HAL 的缓冲区中
mHwcBufferCache.getHwcBuffer(mCurrentBufferSlot, mCurrentBuffer,
&outSlot, &outBuffer);
......
return NO_ERROR;
}
好的, 这里可以看到 FramebufferSurface::advanceFrame 中的主要操作, 便是将合成后的数据, 推入 HAL 层让屏幕展示
- 若渲染队列中无数据, 则继续使用当前帧渲染, 将其推入 HAL 层缓冲
- 若渲染队列中若有数据, 则将当前帧置为上一帧, 新数据置为当前帧, 再将当前帧推入 HAL 层缓冲
到这里, 显示器就可以输出我们合成后的数据帧了
三) 回顾
REFESH 消息会执行如下操作
- rebuildLayerStacks 负责 Layzer 的排序
- 每个显示设备的 Layer 按照 Z 轴进行排序
- doComposition 负责合并 Layer, 并且输出到屏幕
- 调用 doComposeSurfaces 合成所有的 Layer
- 将当前屏幕的 RE::Surface 中的 EGLContext 置为当前线程的 GL 上下文
- 遍历屏幕的 Layer, 绘制 Layer 纹理
- 调用 swapBuffers 将合成后的数据展示到屏幕
- 调用 RE::Surface 的 swapBuffers, 将 EGLSurface 中的数据通过 IGraphicBufferProducer 推入屏幕渲染队列
- 调用了 FramebufferSurface 的 advanceFrame, 将缓冲推给 HAL 进行展示
- 调用 doComposeSurfaces 合成所有的 Layer
总结
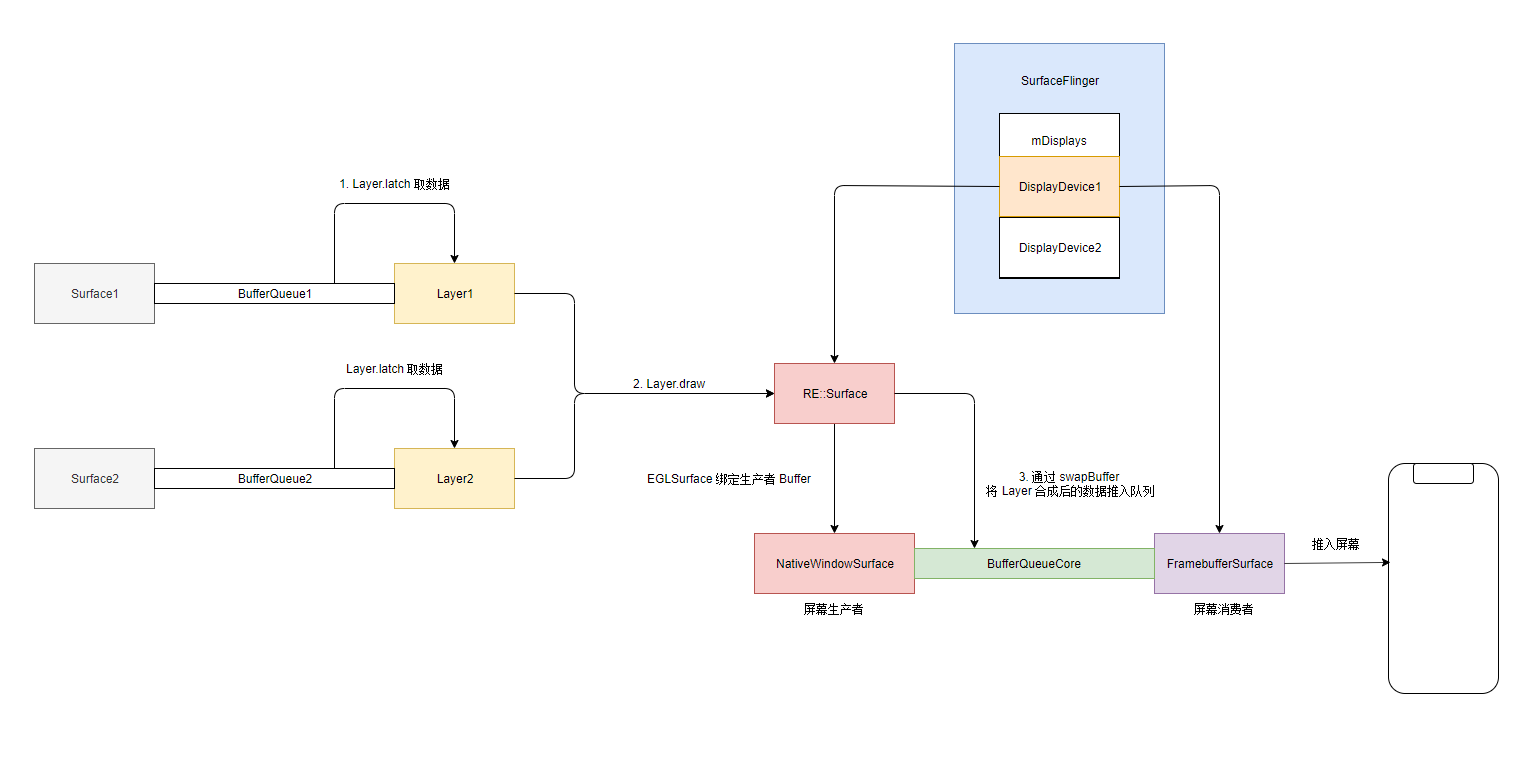
通过本片的分析, 我们得知 SurfaceFlinger 的渲染操作主要有如下几步
- Vsync 的信号分发
- DispSync 处理 HW-VSYNC
- DispSyncThread 分发 SW-VSYNC
- 找寻响应者 DispSyncSource 集合
- 调用 DispSyncSource 分发 SW-VSYNC 到 EventThread
- EventThread 将 SW-VSYNC 写入 Connection 的 BitTube
- EventThread-app: 唤醒应用进程执行绘制操作
- EventThread-sf: 唤醒 SurfaceFlinger 的主线程, 处理 INVALIDATE 消息
- INVALIDATE 消息类型
- 从 Layer 的队列中锁定一个 GraphicBuffer
- REFESH 消息类型
- rebuildLayerStacks 负责 Layzer 的排序
- 每个显示设备的 Layer 按照 Z 轴进行排序
- doComposition 负责合并 Layer, 并且输出到屏幕
- 调用 doComposeSurfaces 合成所有的 Layer
- 将当前屏幕的 RE::Surface 中的 EGLContext 置为当前线程的 GL 上下文
- 遍历屏幕的 Layer, 绘制 Layer 纹理
- 调用 swapBuffers 将合成后的数据展示到屏幕
- 调用 RE::Surface 的 swapBuffers, 将 EGLSurface 中的数据通过 IGraphicBufferProducer 推入屏幕渲染队列
- 调用了 FramebufferSurface 的 advanceFrame, 将缓冲推给 HAL 进行展示
- 调用 doComposeSurfaces 合成所有的 Layer
- rebuildLayerStacks 负责 Layzer 的排序
好的, 到这里 SurfaceFlinger 图像渲染的分析就结束了, 其代码还是非常复杂的, 这里只是梳理了其中的流程, 还有很多细节需要我们去探究