前言
通过之前的分析可知, view 的绘制流程发生在 ViewRootImpl 的 performTraversals 中, 我们这次主要分析 View 的渲染
public final class ViewRootImpl implements ViewParent,
View.AttachInfo.Callbacks, ThreadedRenderer.DrawCallbacks {
private void performTraversals(){
if (!cancelDraw && !newSurface) {
......
// 调用了 performDraw
performDraw();
} else {
......
}
}
private void performDraw() {
try {
// 执行绘制
boolean canUseAsync = draw(fullRedrawNeeded);
......
} finally {
......
}
}
private boolean draw(boolean fullRedrawNeeded) {
......
final Rect dirty = mDirty;
if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) {
// 若开启了硬件加速, 则使用 OpenGL 的 ThreadedRenderer 进行绘制
if (mAttachInfo.mThreadedRenderer != null && mAttachInfo.mThreadedRenderer.isEnabled()) {
......
mAttachInfo.mThreadedRenderer.draw(mView, mAttachInfo, this, callback);
} else {
// 若我们没有开启硬件加速, 则调用 drawSoftware
if (!drawSoftware(surface, mAttachInfo, xOffset, yOffset,
scalingRequired, dirty, surfaceInsets)) {
return false;
}
}
}
.......
}
}
好的可以看到, View 的绘制, 可能有两种实现方式
- 调用 ThreadedRenderer.draw() 进行 GPU 绘制
- 调用 ViewRootImpl.drawSoftware() 进行 CPU 绘制
GPU 绘制又称之为硬件加速绘制, 在 Android 4.0 之后是系统默认开启的, 这里我们先分析比较简单的软件渲染流程
软件渲染
public final class ViewRootImpl implements ViewParent,
View.AttachInfo.Callbacks, ThreadedRenderer.DrawCallbacks {
private boolean draw(boolean fullRedrawNeeded) {
......
final Rect dirty = mDirty;
if (!dirty.isEmpty() || mIsAnimating || accessibilityFocusDirty) {
if (mAttachInfo.mThreadedRenderer != null && mAttachInfo.mThreadedRenderer.isEnabled()) {
......
} else {
// 若我们没有开启硬件加速, 则调用 drawSoftware
if (!drawSoftware(surface, mAttachInfo, xOffset, yOffset,
scalingRequired, dirty, surfaceInsets)) {
return false;
}
}
}
.......
}
}
可以看到软件渲染调用了 drawSoftware 方法, 接下来我们继续探究软件渲染是如何执行的
public final class ViewRootImpl implements ViewParent,
View.AttachInfo.Callbacks, ThreadedRenderer.DrawCallbacks {
private boolean drawSoftware(Surface surface, AttachInfo attachInfo, int xoff, int yoff,
boolean scalingRequired, Rect dirty, Rect surfaceInsets) {
final Canvas canvas;
try {
......
// 1. 通过 Surface 的 lock 操作, 获取一个画笔, 这个画笔是 Skia 的上层封装
canvas = mSurface.lockCanvas(dirty);
......
}
......
try {
......
try {
......
// 2. 调用了 DecorView 的 draw 方法
mView.draw(canvas);
......
} finally {
.......
}
} finally {
// 3. 解锁画笔, 将数据发送给 SurfaceFlinger
surface.unlockCanvasAndPost(canvas);
......
}
return true;
}
}
好的, 可以看到软件绘制主要有三步
- 首先是通过 Surface 的 lockCanvas 获取一个画笔 Canvas, 它是 Android 2D 图像库 Skia 的一个上层封装
- 然后调用了 View 的 draw 方法
- 最后调用了 unlockCanvasAndPost 解锁画笔, 将数据同步给 SurfaceFinger 缓冲区, 进行渲染
一. Surface.lockCanvas
public class Surface implements Parcelable {
private final Canvas mCanvas = new CompatibleCanvas();
public Canvas lockCanvas(Rect inOutDirty)
throws Surface.OutOfResourcesException, IllegalArgumentException {
synchronized (mLock) {
......
// 调用 nativeLockCanvas 获取一个 Surface(Native) 的强引用对象, 表示绘制开始了
mLockedObject = nativeLockCanvas(mNativeObject, mCanvas, inOutDirty);
return mCanvas;
}
}
private static native long nativeLockCanvas(long nativeObject, Canvas canvas, Rect dirty)
throws OutOfResourcesException;
}
好的, 可以看到 Surface.lockCanvas 操作, 主要是调用了 nativeLockCanvas
这个 native 方法的作用是处理 Surface 与 Canvas 的绑定操作, 接下来看看他们是如何绑定的
Surface 与 Canvas 的绑定
// /frameworks/base/core/jni/android_view_Surface.cpp
static jlong nativeLockCanvas(JNIEnv* env, jclass clazz,
jlong nativeObject, jobject canvasObj, jobject dirtyRectObj) {
sp<Surface> surface(reinterpret_cast<Surface *>(nativeObject));
......
// 1. 将 Java 的 Rect 数据, 导入到 C 的 Rect 中
Rect dirtyRect(Rect::EMPTY_RECT);
Rect* dirtyRectPtr = NULL;
if (dirtyRectObj) {
dirtyRect.left = env->GetIntField(dirtyRectObj, gRectClassInfo.left);
dirtyRect.top = env->GetIntField(dirtyRectObj, gRectClassInfo.top);
dirtyRect.right = env->GetIntField(dirtyRectObj, gRectClassInfo.right);
dirtyRect.bottom = env->GetIntField(dirtyRectObj, gRectClassInfo.bottom);
dirtyRectPtr = &dirtyRect;
}
// 2. 让 Surface 锁定一个缓冲区 ANativeWindow_Buffer
ANativeWindow_Buffer outBuffer;
status_t err = surface->lock(&outBuffer, dirtyRectPtr);
......
// 3. 创建一个 Bitmap, 用于存储 Canvas 绘制的数据
// 创建图像信息数据
SkImageInfo info = SkImageInfo::Make(outBuffer.width, outBuffer.height,
convertPixelFormat(outBuffer.format),
outBuffer.format == PIXEL_FORMAT_RGBX_8888
? kOpaque_SkAlphaType : kPremul_SkAlphaType,
GraphicsJNI::defaultColorSpace());
SkBitmap bitmap;
ssize_t bpr = outBuffer.stride * bytesPerPixel(outBuffer.format);
bitmap.setInfo(info, bpr);
if (outBuffer.width > 0 && outBuffer.height > 0) {
// 为 Bitmap 关联上 outBuffer 的内存区域
bitmap.setPixels(outBuffer.bits);
} else {
// be safe with an empty bitmap.
bitmap.setPixels(NULL);
}
// 4. 获取 Native 的 Canvas, 让其绑定 Bitmap
Canvas* nativeCanvas = GraphicsJNI::getNativeCanvas(env, canvasObj);
// 为 Canvas 绑定 Bitmap
nativeCanvas->setBitmap(bitmap);
if (dirtyRectPtr) {
// 确定 Canvas 可作用区域
nativeCanvas->clipRect(dirtyRect.left, dirtyRect.top,
dirtyRect.right, dirtyRect.bottom, SkClipOp::kIntersect);
}
......
// 5. 创建 Surface 的一个强引用对象, lockedSurface, 绘制完毕之后再释放
sp<Surface> lockedSurface(surface);
lockedSurface->incStrong(&sRefBaseOwner);
return (jlong) lockedSurface.get();
}
好的, 可以看到其中主要步骤如下
- Surface.lock 锁定一个缓冲区 ANativeWindow_Buffer
- ANativeWindow_Buffer/ANativeWindowBuffer/GraphicBuffer 都可以理解为缓冲区
- 为 Canvas(SkCanvas) 绑定一个 SkBitmap, 并且让其指向 ANativeWindow_Buffer 的内存区域
- 也就是说, Canvas 绘制到这个 Bitmap 上时, 数据就保存在了 ANativeWindow_Buffer 的缓冲区中了
锁定缓冲区
// frameworks/native/libs/gui/Surface.cpp
status_t Surface::lock(
ANativeWindow_Buffer* outBuffer, ARect* inOutDirtyBounds)
{
......
ANativeWindowBuffer* out;
int fenceFd = -1;
// 1. 获取一个 GraphicBuffer
status_t err = dequeueBuffer(&out, &fenceFd);
......
if (err == NO_ERROR) {
// 将 ANativeWindowBuffer 强转成 GraphicBuffer 对象
sp<GraphicBuffer> backBuffer(GraphicBuffer::getSelf(out));
const Rect bounds(backBuffer->width, backBuffer->height);
// 计算需要重绘的区域
Region newDirtyRegion;
if (inOutDirtyBounds) {
newDirtyRegion.set(static_cast<Rect const&>(*inOutDirtyBounds));
newDirtyRegion.andSelf(bounds);
} else {
newDirtyRegion.set(bounds);
}
// 2. 判断是否可以复制上一个缓冲区的数据
const sp<GraphicBuffer>& frontBuffer(mPostedBuffer);
const bool canCopyBack = (frontBuffer != 0 &&
backBuffer->width == frontBuffer->width &&
backBuffer->height == frontBuffer->height &&
backBuffer->format == frontBuffer->format);
// 2.1 若可以复制
if (canCopyBack) {
const Region copyback(mDirtyRegion.subtract(newDirtyRegion));
if (!copyback.isEmpty()) {
copyBlt(backBuffer, frontBuffer, copyback, &fenceFd);
}
}
// 2.2 若不可复制
else {
// 清空这个缓冲区的数据
newDirtyRegion.set(bounds);
mDirtyRegion.clear();
......
}
......
// 3. 锁定这个 GraphicBuffer, 表示已经在使用了
// 通过 GraphicBuffer->lockAsync 获取 图像缓冲区 的 共享内存 映射到当前进程的虚拟首地址
void* vaddr;
status_t res = backBuffer->lockAsync(
GRALLOC_USAGE_SW_READ_OFTEN | GRALLOC_USAGE_SW_WRITE_OFTEN,
newDirtyRegion.bounds(), &vaddr, fenceFd);
if (res != 0) {
......
} else {
// 记录当前被锁定的 GraphicBuffer
mLockedBuffer = backBuffer;
// 4. 将数据注入到 ANativeWindow_Buffer 中
outBuffer->width = backBuffer->width;
outBuffer->height = backBuffer->height;
outBuffer->stride = backBuffer->stride;
outBuffer->format = backBuffer->format;
// 将 GraphicBuffer 共享内存首地址保存到 outBuffer 中
outBuffer->bits = vaddr;
}
}
return err;
}
好的 lock 函数非常有意思
- 它首先获取了一块图像缓冲区的描述 GraphicBuffer
- 然后通过 backBuffer->lockAsync 获取 图像缓冲区 的 共享内存 映射到当前进程的虚拟首地址, 最终将参数保存到 outBuffer 中
GraphicBuffer 相关的操作是由 HAL 的 Gralloc 实现的, 其相关实现可以参考 罗升阳的文章
思考
从这里我们可以看到, GraphicBuffer 的缓存区是一块共享内存区域, 那为什么 Android 不使用 Binder 驱动进行数据的交互呢?
- 因为 Bitmap 的数据量比较大, Binder 在设计之初就确定了它无法进行跨进程数据交互
- 通过共享内存技术, Canvas 的操作就可以直接的同步到共享内存区域了, 无需在进程之间相互拷贝
接下来看看 dequeueBuffer 的函数实现
int Surface::dequeueBuffer(android_native_buffer_t** buffer, int* fenceFd) {
......
uint32_t reqWidth;
uint32_t reqHeight;
PixelFormat reqFormat;
uint64_t reqUsage;
......
int buf = -1; // Buffer 的索引
sp<Fence> fence; // 围栏
// 可以看到通过 mGraphicBufferProducer 这个 Binder 代理对象 dequeueBuffer 获取一个缓冲区
// 将 BufferSlot 保存在索引位置 buf 处
status_t result = mGraphicBufferProducer->dequeueBuffer(&buf, &fence, reqWidth, reqHeight,
reqFormat, reqUsage, &mBufferAge,
enableFrameTimestamps ? &frameTimestamps
: nullptr);
......
// 从 BufferSlot 中获取一个 GraphicBuffer
sp<GraphicBuffer>& gbuf(mSlots[buf].buffer);
......
*buffer = gbuf.get();
......
return OK;
}
// frameworks/native/libs/gui/IGraphicBufferProducer.cpp
virtual status_t dequeueBuffer(int* buf, sp<Fence>* fence, uint32_t width, uint32_t height,
PixelFormat format, uint64_t usage, uint64_t* outBufferAge,
FrameEventHistoryDelta* outTimestamps) {
Parcel data, reply;
bool getFrameTimestamps = (outTimestamps != nullptr);
data.writeInterfaceToken(IGraphicBufferProducer::getInterfaceDescriptor());
data.writeUint32(width);
data.writeUint32(height);
data.writeInt32(static_cast<int32_t>(format));
data.writeUint64(usage);
data.writeBool(getFrameTimestamps);
status_t result = remote()->transact(DEQUEUE_BUFFER, data, &reply);
if (result != NO_ERROR) {
return result;
}
*buf = reply.readInt32();
*fence = new Fence();
result = reply.read(**fence);
......
result = reply.readInt32();
return result;
}
可以看到, 这里主要是调用了 mGraphicBufferProducer->dequeueBuffer 函数, 即通过 Binder 驱动从远端的 SurfaceFlinger 进程, 获取一个空闲的缓冲区 GraphicBuffer
- mSlots: 为存储空闲缓冲区的数组
- buf: 空闲缓冲区的索引
- Fence: 为围栏操作, 用于在使用时, 等待 GPU 释放对这块 Buffer 的使用
- 使用 Fence 就能够等这个 GraphicBuffer 真正要被消费者用到时再堵塞, 而那之前CPU和GPU是能够并行工作的, 这样相当于实现了临界资源的lazy passing
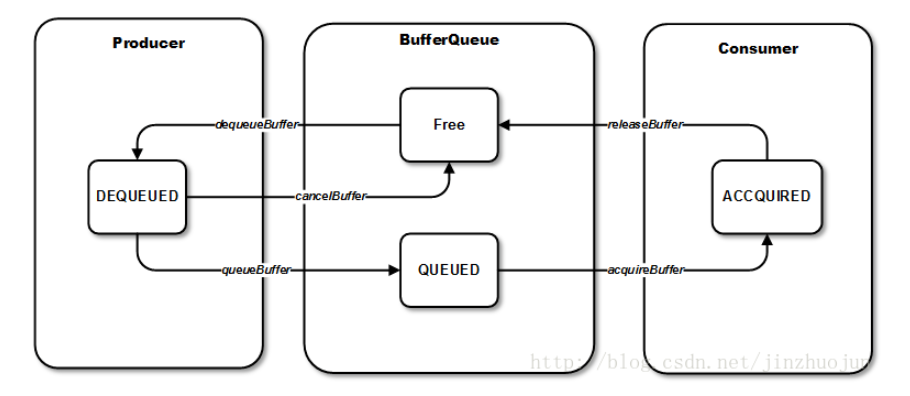
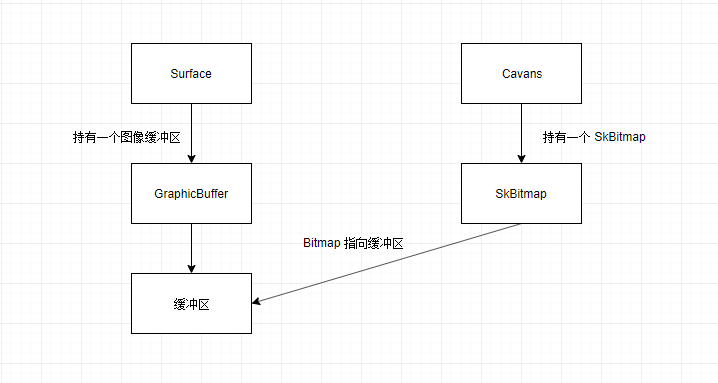
回顾
Surface.lockCanvas 操作主要做了如下的事情
- 获取一个 GraphicBuffer
- 创建一个 SkBitmap, 并让其像素数据指向 GraphicBuffer 的内存地址
- 为 SkCanvas 绑定 SkBitmap
- Canvas 绘制的所有数据都会写入到 Bitmap 中, 因此会更新到 GraphicBuffer 的缓冲中
二. View 绘制的分发
public class View {
public void draw(Canvas canvas) {
......
/*
* Draw traversal performs several drawing steps which must be executed
* in the appropriate order:
*
* 1. Draw the background
* 2. If necessary, save the canvas' layers to prepare for fading
* 3. Draw view's content
* 4. Draw children
* 5. If necessary, draw the fading edges and restore layers
* 6. Draw decorations (scrollbars for instance)
*/
// Step 1, draw the background, if needed
int saveCount;
// skip step 2 & 5 if possible (common case)
final int viewFlags = mViewFlags;
boolean horizontalEdges = (viewFlags & FADING_EDGE_HORIZONTAL) != 0;
boolean verticalEdges = (viewFlags & FADING_EDGE_VERTICAL) != 0;
if (!verticalEdges && !horizontalEdges) {
// Step 3, draw the content
if (!dirtyOpaque) {
onDraw(canvas);
}
// Step 4, draw the children
dispatchDraw(canvas);
// Overlay is part of the content and draws beneath Foreground
if (mOverlay != null && !mOverlay.isEmpty()) {
mOverlay.getOverlayView().dispatchDraw(canvas);
}
// Step 6, draw decorations (foreground, scrollbars)
onDrawForeground(canvas);
// Step 7, draw the default focus highlight
drawDefaultFocusHighlight(canvas);
return;
}
......
}
}
好的, 很简单这就是 View 的绘制流程的分发, 这里不再赘述了
接下来看看 unlockCanvasAndPost 的操作
三. Surface.unlockCanvasAndPost
public class Surface implements Parcelable {
private void unlockSwCanvasAndPost(Canvas canvas) {
......
try {
// 处理 Surface 与 Canvas 的解绑操作
nativeUnlockCanvasAndPost(mLockedObject, canvas);
} finally {
// 释放 Surface(Native) 的强引用, 表示绘制结束了
nativeRelease(mLockedObject);
mLockedObject = 0;
}
}
}
private static native void nativeUnlockCanvasAndPost(long nativeObject, Canvas canvas);
可以看到调用了 nativeUnlockCanvasAndPost 处理 Surface 与 Canvas 的解绑操作, 接下来看看具体的实现
// frameworks/base/core/jni/android_view_Surface.cpp
static void nativeUnlockCanvasAndPost(JNIEnv* env, jclass clazz,
jlong nativeObject, jobject canvasObj) {
sp<Surface> surface(reinterpret_cast<Surface *>(nativeObject));
if (!isSurfaceValid(surface)) {
return;
}
// 让 Canvas 指向一张空 Bitmap, 与 Surface 的 GraphicBuffer 解绑
Canvas* nativeCanvas = GraphicsJNI::getNativeCanvas(env, canvasObj);
nativeCanvas->setBitmap(SkBitmap());
// unlock surface
status_t err = surface->unlockAndPost();
......
}
// frameworks/native/libs/gui/Surface.cpp
status_t Surface::unlockAndPost()
{
......
int fd = -1;
// 释放对缓冲区的锁定操作
status_t err = mLockedBuffer->unlockAsync(&fd);
......
// 将缓冲区推入队列
err = queueBuffer(mLockedBuffer.get(), fd);
......
return err;
}
可以看到这里调用了 queueBuffer 函数, 与 dequeueBuffer 类似的, 它的作用是将这块缓冲区描述推入远端进程 SurfaceFlinger 的待处理的队列
SurfaceFlinger 进程作为消费者, 就可以从队列中取数据, 渲染到屏幕了, 这里关于 SurfaceFlinger 的渲染, 到后面再进行分析
回顾
到这里 Surface 与 Canvas 解绑的操作便完成了, 他们整体的依赖关系如下
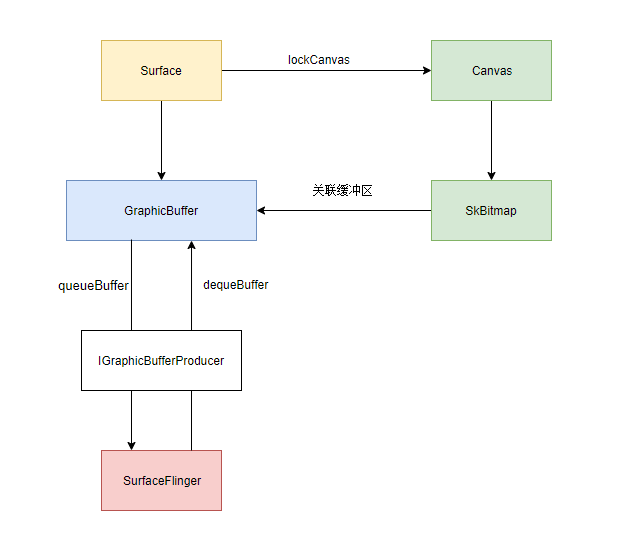
总结
Android 端软件渲染的引擎为 Skia, 其软件渲染的工作机制即使用 Canvas 将数据绘制到 Surface 的 GraphicBuffer 中, 它的工作流程如下
- //////////////////////// Step1 /////////////////////////
- Surface 锁定一个 GraphicBuffer 缓冲区
- 让 SkiaCanvas 的 SkBitmap 绑定缓冲区的共享内存
- 意味着 Bitmap 的数据直接存储在缓冲区上了
- //////////////////////// Step2 /////////////////////////
- 分发 View 绘制
- //////////////////////// Step3 /////////////////////////
- Surface 释放 GraphicBuffer 缓冲区, 并将其推入 SurfaceFlinger 的渲染队列
- SurfaceFlinger 获取渲染数据输出到屏幕
到这里软件渲染就分析完毕了, 关于硬件渲染, 则需要 OpenGL 的基础, 因此后面笔者打算学习一下图像图像学的知识, 来夯实自己的内功基础